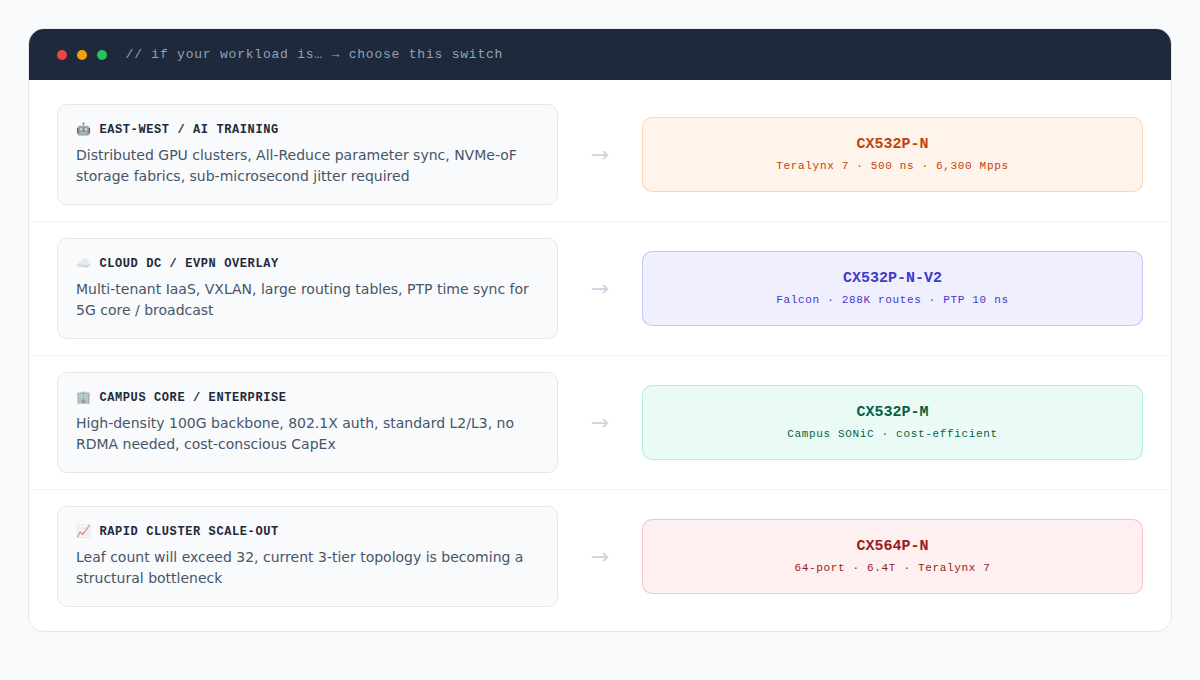
In today’s data center infrastructure evolution, 100G has unambiguously become the mainstream standard. Whether it’s the full-scale rollout across public cloud hyperscaler networks or the upgrade and overhaul of mid-to-large enterprise private clouds, 100G ports have secured their position at the heart of network architectures — thanks to exceptional price-to-performance ratios, a mature ecosystem, and solid support for high-bandwidth workloads. Yet as cloud computing pushes deeper and the AI large-model boom ignites an unprecedented compute frenzy, the demands placed on data center switches — in terms of throughput, latency, power consumption, and software openness — are fundamentally diverging. Blindly chasing the highest specs or defaulting to the cheapest option will almost certainly plant landmines that detonate when you go to production. Network architects must carefully match the right physical platform to their actual deployment scenario — whether that’s a high-density AI compute fabric, a large-scale multi-tenant cloud, or a traditional campus core aggregation layer. This article dives deep into today’s mainstream 100G switch silicon options and pairs them with real-world use cases to give you a professional, no-nonsense selection guide.
The 32×100G Silicon Battle: The Underlying Contest Between Marvell Teralynx and Falcon
In the 32×100G market segment (driven by 3.2 Tbps aggregate switching capacity), the choice of silicon directly defines the core DNA of a switch. Within this space, the Teralynx and Falcon series — both backed by Marvell’s technology stack — represent the two fundamental camps that any serious network engineer will inevitably encounter. Comparing them isn’t a simple matter of spec sheets. It’s a deep look at two different network philosophies, each surgically tailored to distinct use cases.
Marvell Teralynx: The Vanguard of High Bandwidth and Extreme Low Latency
From the ground up, the Teralynx chip was designed to deliver unmatched data forwarding efficiency inside large-scale, flattened Clos data center architectures. It employs a highly optimized, single-pipeline architecture, and its network philosophy can be summed up as: “faster, smoother, built for next-generation networks where microsecond latency is non-negotiable.”
Shattering the Latency Barrier — Hitting the Microsecond Pain Point Head-On
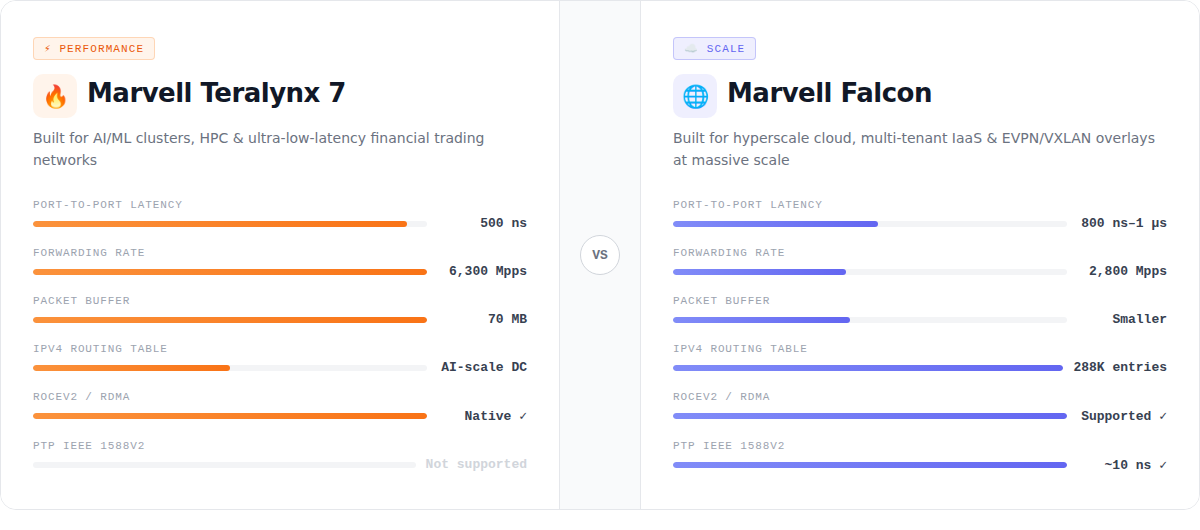
Teralynx 7 achieves a remarkably low cut-through port-to-port latency of just 500 nanoseconds (ns). By comparison, competing chips in the same class typically operate in the 800 ns to 1 μs range. That 300–500 ns gap at the silicon level is often the deciding factor in distributed AI training and inference clusters, high-frequency trading (HFT) systems, and financial backbone networks requiring real-time synchronization — determining the effective throughput ceiling of a GPU cluster and the outcome of a trade.
Staggering Small-Packet Throughput — Crushing High-Concurrency Traffic
The chip supports up to 6,300 Mpps (million packets per second) — nearly double the throughput of many conventional 3.2T chips. In inference clusters, NVMe storage fabrics, or highly concurrent microservices environments, the network is flooded with tiny, rapid-fire packets. Teralynx 7’s wire-rate forwarding capacity at double the throughput ensures small packets never stack up and workloads run smoothly.
70 MB Jumbo Buffer — Building the Foundation for Lossless Ethernet
Against micro-burst traffic, Teralynx 7 brings a 70 MB dynamic packet buffer — again, roughly twice that of comparable chips. Combined with lossless Ethernet technologies (RoCEv2, ECN, PFC), it delivers outstanding burst absorption. Even at peak traffic during HPC or large-scale deep learning workloads, it aggressively reduces packet drops and sustains stable lossless performance.
Teralynx 7’s ideal stage: AI/ML training and inference clusters; HPC environments using RDMA or RoCE; financial institutions and ultra-low-latency trading platforms; and latency-sensitive data center Leaf and Spine tiers.
Marvell Falcon: The Convergence of High Density, Energy Efficiency, and Flexible Architecture
If Teralynx is engineered for extreme performance and AI low-latency networks, Falcon takes an entirely different route — its focus is on making networks in large-scale cloud data centers more stable, more power-efficient, and more scalable. It’s not a chip built to chase peak speed. It’s a quintessential cloud-era switching chip: emphasizing density, energy efficiency, and adaptability to the complex traffic models of multi-tenant environments.
Unrivaled Routing Table Capacity — Capital for Horizontal Scale-Out
Falcon supports up to 288K IPv4 and 144K IPv6 routing table entries — among the highest in its class. In hyperscale cloud architectures, whether handling large-scale East-West traffic or planning for North-South flows, this massive hardware routing table means network architects can deploy it directly as an edge router or at the Spine/Leaf tier, perfectly sustaining the routing density demands of large tenant networks.
128K MAC Address Space — Handling a Flood of Virtual Endpoints
Modern data centers host tens of thousands of VMs and container instances. Falcon’s 128K MAC address entries provide strong underlying capacity for multi-tenant cloud providers and Kubernetes-heavy container environments. Even in large-scale VXLAN EVPN overlay networks, it handles frequent migrations of massive virtual endpoints with ease, sustaining enormous Layer 2 domains.
From a traffic model perspective, Falcon gravitates toward the typical demands of cloud-native data centers: high-volume East-West traffic, mixed North-South access, and multi-tenant isolation. That’s precisely why it feels natural in EVPN/VXLAN networks, readily serving as Leaf, Spine, or even ToR depending on the design.
Nanosecond-Precision Timing — Full PTP (IEEE 1588v2) Support
Beyond raw performance, Falcon has one easily overlooked but critically important capability: PTP time synchronization precision down to approximately 10 ns. For broadcast-grade ultra-HD live production, low-latency media streaming, and financial distributed database synchronization, this high-precision time alignment is essential — ensuring reliable cross-node event ordering and latency measurement.
Falcon’s ideal stage: Hyperscale public cloud and edge data centers; multi-tenant IaaS or colocation environments; overlay-heavy networks (VXLAN, EVPN); and standard L3 Spine-Leaf topologies where it can flexibly play ToR, Leaf, or Spine roles.
Contrast of 32×100G Switch: Marvell Falcon vs. Teralynx Platforms
| Feature / Spec | Teralynx 7 Platform | Falcon Platform |
| Positioning | Ultra-low-latency / High-performance | Large-scale routing / Cloud flexibility |
| Latency | 500 ns (best-in-class) | Higher (800 ns – 1 μs) |
| Forwarding Rate | 6,300 Mpps | 2,800 Mpps |
| Buffer Size | 70 MB | Smaller |
| Routing Table Scale | Moderate | 288K (IPv4) / 144K (IPv6) |
| Use Case Fit | AI, HPC, Financial Trading, Spine/Core | Cloud DC, Multi-Tenant, Leaf/ToR |
| Price | More expensive than Falcon | Less expensive than Teralynx 7 |
Deep Dive — Three Core Models: CX532P-N, CX532P-N-V2, and CX532P-M
CX532P-N: The Lossless Vanguard for HPC and AI Workloads
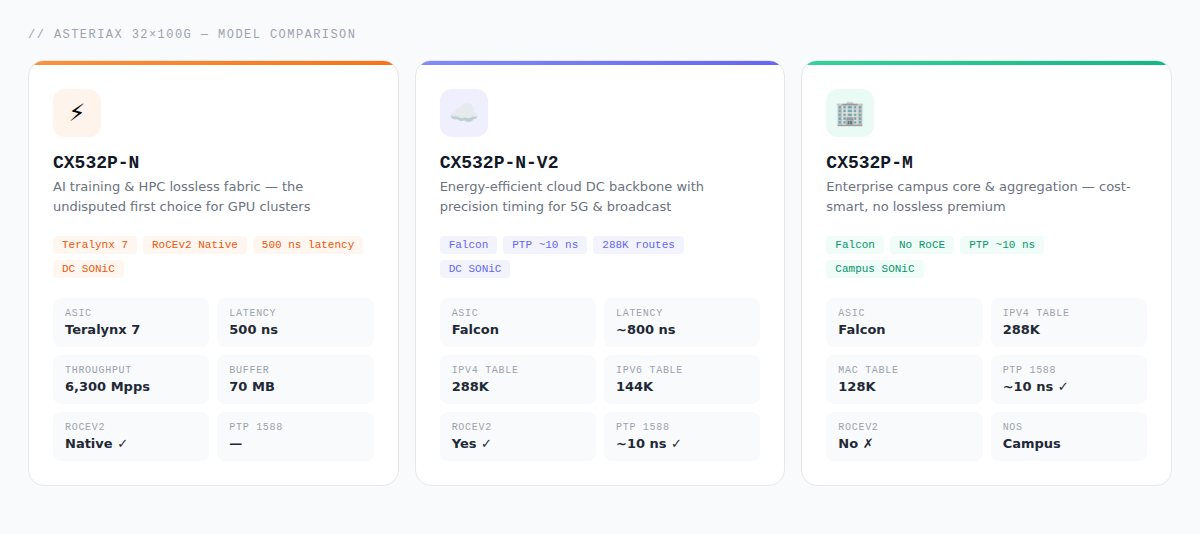
Built on the Marvell Teralynx 7 high-performance silicon platform, the CX532P-N is pure-blooded performance hardware. Its defining advantage is end-to-end latency as low as 500 ns, with native hardware-level support for RoCE v2 (RDMA over Converged Ethernet) and lossless Ethernet control mechanisms.
In distributed AI training (e.g., All-Reduce parameter synchronization for large models) or high-performance NVMe storage clusters (NVMe-oF), there is relentless, high-frequency data synchronization between GPUs and storage nodes. Under this extreme high-concurrency, high-burst traffic topology, the CX532P-N natively leverages PFC (Priority Flow Control) and ECN (Explicit Congestion Notification) to fundamentally eliminate packet loss from network congestion, ensuring ultra-low jitter and wire-rate forwarding. If you’re building a lossless backend network for AI compute interconnects, machine learning clusters, or hyperscale high-performance cloud computing, the CX532P-N is the undisputed first choice.
CX532P-N-V2: The Backbone of High-Efficiency Data Centers and Precision Timing Networks
As the V2 successor, the CX532P-N-V2 pivots to the Marvell Falcon platform. While maintaining 3.2 Tbps of high-caliber forwarding performance, Falcon’s advanced architecture significantly improves overall power consumption and thermal management — a high energy-efficiency profile that meaningfully reduces long-term PUE in the data center.
Unlike the N series with its singular focus on extreme low latency, the CX532P-N-V2 exhibits strong functional versatility:
- Nanosecond-precision timing: Full PTP (IEEE 1588v2) support at up to 10 ns precision makes it a natural fit for broadcast-grade ultra-HD live production, low-latency media streaming, 5G core transit, and financial distributed database synchronization — any workload with strict absolute timestamp alignment requirements.
- Massive routing table capacity: Leveraging Falcon’s silicon advantages, the model carries up to 288K (IPv4) / 144K (IPv6) hardware routing table entries. On top of full RoCE v2 support, this large table capacity makes it a perennial workhorse for cloud data centers, large-scale multi-tenant virtualization environments, and ToR/Leaf nodes in standard Spine/Leaf architectures.
CX532P-M: The Pragmatic Powerhouse for Campus Cores and Enterprise Networks
Compared to the previous two, the CX532P-M carves out a precisely targeted role — and network planners need to understand it clearly upfront: the CX532P-M is purpose-built for the core layer of mid-to-large enterprise and campus networks. At the NOS and firmware level, it does not support the RoCE (RDMA) protocol stack. That means it has no place in the backend fabric of an AI compute cluster. But that’s precisely where its cost efficiency comes from. Traditional campus networks have no need for complex lossless queuing or microsecond compute scheduling. What they require is high-density 100G backbone aggregation, high availability, and the white-box automated operations capability that the Enterprise SONiC for Campus software ecosystem delivers.
At the hardware level, it still inherits Falcon’s excellent PTP time synchronization (10 ns precision), handling campus AV/broadcast matrix and multimedia conferencing systems with ease. More impressively, it retains the full 288K (IPv4) / 144K (IPv6) routing table — meaning that even as a campus switch, it carries the hardcore foundation needed for complex L3 routing in large cloud data centers, colocation, or overlay networks, should the need arise. The CX532P-M strips away the costly lossless network software premium of data center-grade platforms and focuses that budget squarely on high-capacity campus backbone forwarding. If your goal is carrying the high-speed backbone across classroom buildings and office towers, or serving as the core aggregation for corporate headquarters, the CX532P-M is the professionally grounded, cost-smart choice.
Deep Comparison of AsteriaX 32×100G Switch Models
| Feature | CX532P-N | CX532P-N-V2 | CX532P-M |
| Physical Port Config | 32 × 100G QSFP28 | 32 × 100G QSFP28 | 32 × 100G QSFP28 |
| Underlying ASIC | Marvell Teralynx 7 | Marvell Falcon | Marvell Falcon |
| RoCE v2 / RDMA Support | Fully supported | Fully supported | Not supported |
| PTP Time Sync (IEEE 1588v2) | Not supported | Fully supported (up to 10 ns precision) | Fully supported (up to 10 ns precision) |
| Network OS (NOS) | Enterprise SONiC (Data Center Edition) | Enterprise SONiC (Data Center Edition) | Enterprise SONiC (Campus Edition) |
| Target Deployment | AI training & inference clusters, HPC, hyperscale cloud Spine | Next-gen energy-efficient cloud DCs, high-precision telemetry/sync networks, standard Spine/Leaf | Mid-to-large enterprise networks, campus core / aggregation layer |
Advanced Consideration: When Should You Seriously Look at 64×100G (e.g., the CX564P-N)?
When planning networks, many teams default to “if 32 ports aren’t enough, just stack more switches.” At small scale, that’s fine. But when network size explodes due to AI compute or large clusters, continuing to stack 32-port switches is just masking architectural bloat with hardware. A 64-port flagship like the CX564P-N — built on Teralynx 7 — doesn’t just double your ports. It streamlines the network on two distinct dimensions:
Architecture Level: Eliminate an Entire Network Tier
In a standard topology, one 32-port Spine can connect 32 Leaf switches. Once Leaf count grows beyond that, you’re forced to add another Spine tier for transit.
Switch to the 64-port CX564P-N and a single Spine can directly connect 64 Leaf switches, collapsing what would have been a three-tier topology back to two tiers. One fewer hop matters enormously for latency-critical AI training:
- Eliminate multi-hop latency: One fewer hop means GPU parameter synchronization doesn’t have to wait around.
- Double the stability: Cut the cabling and device count in half, and physical failure rates drop exponentially.
Data Center Floor Level: Do the Hidden Math on Space and Power
Many teams draw beautiful topologies on slides, then walk into the data center to find they’re immediately blocked by insufficient rack U-space or power budgets. Using two 32-port switches to approximate the capacity of one 64-port looks flexible on paper, but it’s a losing proposition on hidden costs:
- Double the operations burden: Twice the devices means twice the management IPs and twice the fiber complexity.
- Lower power consumption: The CX564P-N is a 2U device, but because it runs on a single highly integrated 6.4T chip, its overall power draw and thermal efficiency are far better than two 3.2T switches combined — a meaningful win for data center PUE audits.
The 4 Golden Standards for Choosing a 100G Switch
In real procurement and network design, many teams fall into the trap of “spec sheet tunnel vision” — buying on numbers and port counts without aligning to actual workloads. To find the right 100G switch, you need to look at your budget and business requirements together. The following four key recommendations can save you from spending hundreds of thousands learning the hard way:
1. Know Your Traffic Model — Don’t Let North-South Reliability Wreck Your East-West Fate
Before selecting, understand whether your traffic is racing around inside the data center or constantly flowing in and out of the public internet.
- East-West traffic (AI training): If your workload is distributed AI training or large-model fine-tuning, the traffic profile is ultra-high concurrency with instantaneous bursts. Latency is the primary killer. The answer is clear: choose the Teralynx platform (e.g., CX532P-N) with end-to-end 500 ns latency and 70 MB buffer — no second-guessing required.
- North-South traffic (internet-facing): If your switches are primarily handling external web access and application delivery, the traffic profile is steady and sustained. There’s no need to fight for sub-microsecond extreme latency. The Falcon platform — stable, feature-rich, with a massive routing table — is the right backbone here.
2. Project Your Network’s Lifecycle — Don’t Let Today’s Savings Become Tomorrow’s Reconstruction Costs
Network planning needs to look ahead.
- If your cluster is in a high-growth phase or clearly in the AI compute camp with inevitable expansion over the next 1–2 years, continuing to stack 32-port switches is loading the future network with structural debt. Moving directly to the 64×100G CX564P-N is the architecture that holds up long-term.
- If you’re working with a mature, architecturally stable network with minimal expansion demand, the 32×100G platform is clearly more economical and flexible on initial capex.
3. Don’t Let Campus Cores Ride the AI Hype — Refuse to Pay a Premium for Features You’ll Never Use
Many enterprise IT teams, when upgrading campus networks, fall for the trend of buying “AI-optimized” or “HPC-grade” data center switches. That’s pure budget waste.
Campus networks need high-density 100G backbone aggregation, 802.1X authentication, standard Layer 2/3 protocols, and IT automation that’s easy to operate and maintain. You do not need to pay expensive software licensing fees for nanosecond-level lossless queuing. Choosing a device like the CX532P-M running Enterprise SONiC for Campus — which strips away the data center lossless premium — is the genuinely cost-effective and purpose-fit professional approach.
4. The Ultimate Cost-vs-Performance Formula
If you’re still weighing it out, print these three lines directly onto your selection whiteboard:
- Marvell Falcon (e.g., CX532P-N-V2): The balanced “all-rounder” — the price-performance foundation for standard public cloud, multi-tenant virtualization, and high-precision time synchronization networks.
- Marvell Teralynx (e.g., CX532P-N / CX564P-N): The enthusiast “performance beast” — purpose-built for AI/ML compute training, ultra-low-latency HFT financial trading, and NVMe-oF extreme storage.
- Campus Enterprise-Grade (e.g., CX532P-M): The pragmatic “backbone stalwart” — retaining Falcon’s massive routing table and high bandwidth while serving as the high-speed artery for enterprise and campus networks.
Conclusion
Building a data center network has never been a pure “spec arms race.” It’s an engineering art of balance and fit. From the silicon-level Teralynx vs. Falcon debate, to the scenario-specific differentiation across the CX532P-N, CX532P-N-V2, and CX532P-M, to the architectural leap of 64×100G — a clear-eyed definition of your use case is always the first principle. Hopefully this deep-dive breakdown helps you cut through the noise of the hardware market and precisely identify the network foundation that best fits your business — laying a rock-solid highway for the workload explosion of the cloud computing and AI era.
Final Summary: 32×100G Model Comparison
| Attribute | CX532P-N | CX532P-N-V2 | CX532P-M |
| Chip Platform | Marvell Teralynx 7 | Marvell Falcon | Marvell Falcon |
| Positioning | AI / HPC Lossless Fabric | Cloud Data Center Backbone | Campus / Enterprise Core |
| Architecture Focus | Ultra-low latency, deterministic forwarding | Balanced performance, efficiency, scalability | Enterprise routing & aggregation |
| Latency | ≈500 ns | Higher (800 ns – 1 μs) | Higher (800 ns – 1 μs) |
| RoCE Support | Yes (native RoCE v2) | Yes (RoCE v2 supported) | No |
| PTP Accuracy | Not primary focus | Up to ~10 ns (IEEE 1588v2) | Up to ~10 ns (IEEE 1588v2) |
| Routing Table Capacity | High-performance DC scale (AI-oriented) | 288K IPv4 / 144K IPv6 | 288K IPv4 / 144K IPv6 |
| OS | Enterprise SONiC (Data Center Edition) | Enterprise SONiC (Data Center Edition) | Enterprise SONiC (Campus Edition) |
| Key Use Cases | AI training, NVMe-oF, HPC clusters | Cloud DC, EVPN/VXLAN, multi-tenant networks | Campus core, enterprise backbone, aggregation |