With the rapid advancement of artificial intelligence models, model sizes are growing at an unprecedented pace. From large language models to multimodal models, the number of parameters, training data volume, and computational requirements have far exceeded what traditional single-node or single-cluster architectures can handle.
In this context, relying on a single scaling approach is no longer sufficient to meet the performance, efficiency, and resource utilization demands of modern AI systems. Whether it is increasing the number of GPUs within a single machine or simply scaling out by adding more compute nodes, neither approach alone can fundamentally address the communication overhead and system bottlenecks in large-scale model training.
As a result, three core scaling strategies have gradually emerged in modern AI data center architectures: Scale-Up (vertical scaling), Scale-Out (horizontal scaling), and Scale-Across (cross-domain scaling). These approaches address computational capacity and system scale from different dimensions, and together form the foundation of today’s AI infrastructure design and optimization.
What is Scale-Up?
Scale-Up refers to increasing computational capacity by adding more resources within a single system. In AI infrastructure, this typically means increasing the number of GPUs, memory capacity, and high-speed interconnect bandwidth within a single node (server), rather than distributing workloads across multiple machines.
The core goal of Scale-Up is to maximize intra-node performance, ensuring that communication between accelerators is as fast and low-latency as possible.
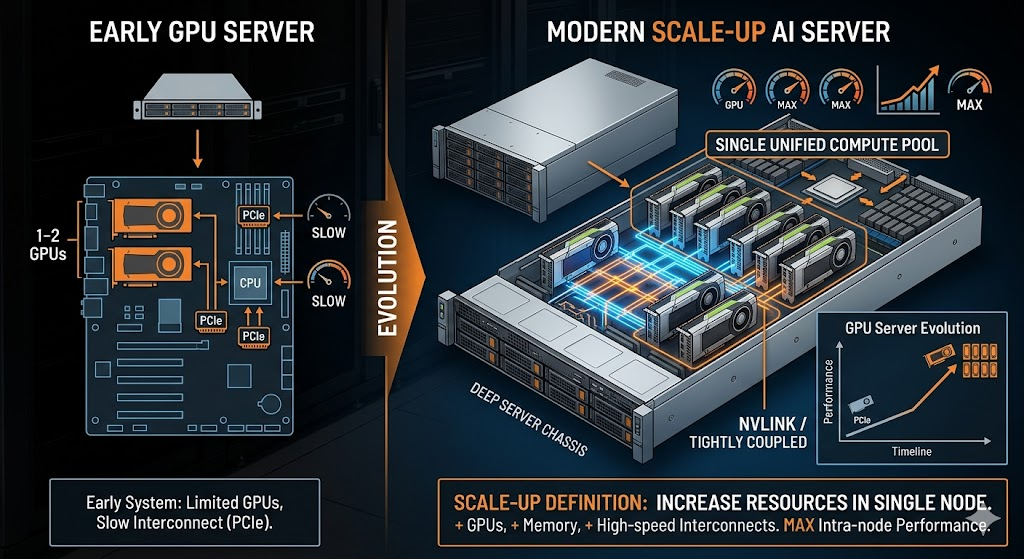
Evolution of GPU Servers
The evolution of GPU servers has been a key driver behind modern Scale-Up architectures.
Early GPU systems typically consisted of only 1–2 GPUs connected via PCIe. However, this approach had clear limitations in terms of bandwidth and latency, making it insufficient for large-scale AI workloads. As model sizes continued to grow, server designs evolved to support 4 GPUs, 8 GPUs, or even more within a single node.
Modern AI servers increasingly rely on tightly integrated multi-GPU architectures, where multiple GPUs can be treated as a unified pool of compute resources. This design enables large-scale tensor operations and model parallelism to be executed more efficiently within a single machine, reducing the need for cross-server communication.
The Importance of NVLink and NVSwitch
NVLink plays a critical role in Scale-Up architectures. Compared to traditional PCIe connections, NVLink provides significantly higher bandwidth and lower latency, enabling more efficient data exchange between GPUs.
However, in modern high-end GPU servers, point-to-point NVLink connections alone are no longer sufficient for scaling to many GPUs. As a result, NVLink is typically combined with NVSwitch to build a fully connected high-speed switching fabric within a single node.
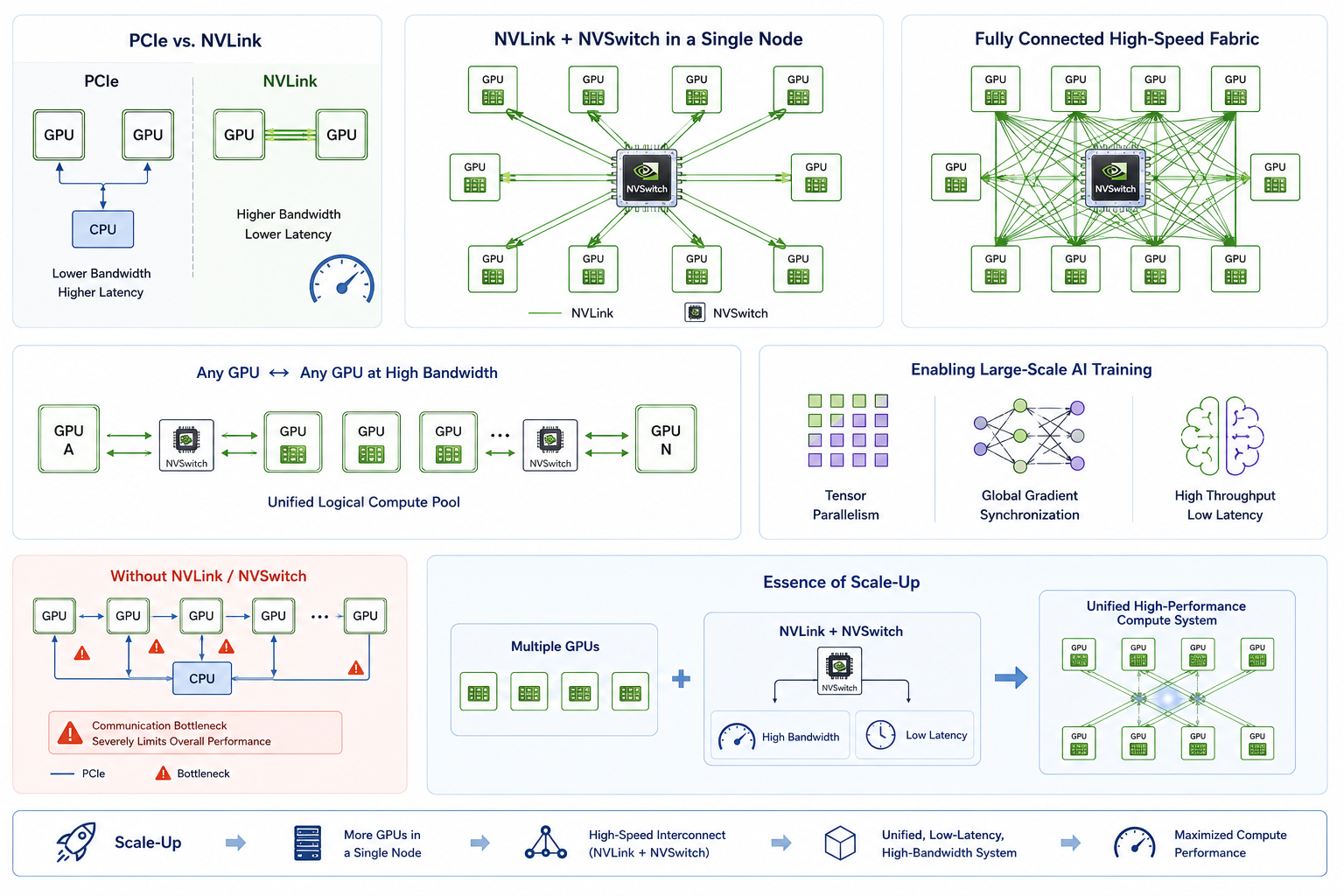
The introduction of NVSwitch allows any GPU to communicate with any other GPU at high bandwidth, effectively merging multiple discrete GPUs into a unified logical compute pool. This architecture is essential for AI training workloads that require frequent large-scale inter-GPU communication, such as tensor parallelism and global gradient synchronization.
Without high-speed interconnect technologies like NVLink and NVSwitch, the overall performance of Scale-Up systems would be severely constrained. The primary bottleneck would shift from compute capability to inefficient GPU-to-GPU communication.
The essence of Scale-Up is to integrate multiple GPUs within a single node into a unified, low-latency, high-bandwidth computing system by increasing GPU count and leveraging high-speed interconnects such as NVLink and NVSwitch.
| Dimension | PCIe | NVLink | NVSwitch |
| Technology Type | General-purpose I/O bus | High-speed GPU interconnect | GPU switching fabric |
| Design Goal | Connect diverse devices (GPU, SSD, NIC) | Accelerate GPU-to-GPU communication | Build a unified multi-GPU compute domain |
| Typical Topology | Tree (Root Complex-based) | Point-to-point (Mesh/Ring) | Fully connected Crossbar |
| AI Optimization | ❌ No | ✅ Yes | ✅ Yes (advanced) |
| GPU Communication Path | Via CPU / PCIe switch | Direct GPU-to-GPU | Through NVSwitch ASIC |
| Latency | Relatively high | Low | Extremely low |
| Bandwidth (per link) | PCIe Gen4 x16 ≈ 32 GB/sPCIe Gen5 x16 ≈ 64 GB/s | NVLink v4 ≈ 50 GB/s per direction per link (aggregated via multiple links) | Aggregate bandwidth up to TB/s scale |
| Scalability | Limited (mainly inter-node) | Moderate (within a node, limited GPU count) | High (8/16+ GPUs fully interconnected) |
| Communication Model | CPU-centric | GPU Peer-to-Peer | Global GPU memory fabric |
| All-to-All Efficiency | ❌ Poor | ⚠️ Moderate | ✅ Excellent |
| Unified Memory Support | ❌ No | ⚠️ Partial | ✅ Strong (coherent memory space) |
| Typical Use Cases | General-purpose servers | 4–8 GPU servers | DGX / HGX / large-scale AI training |
| Representative Architectures | Standard x86 servers | NVLink Bridge / HGX platforms | NVSwitch-based systems (e.g., DGX H100) |
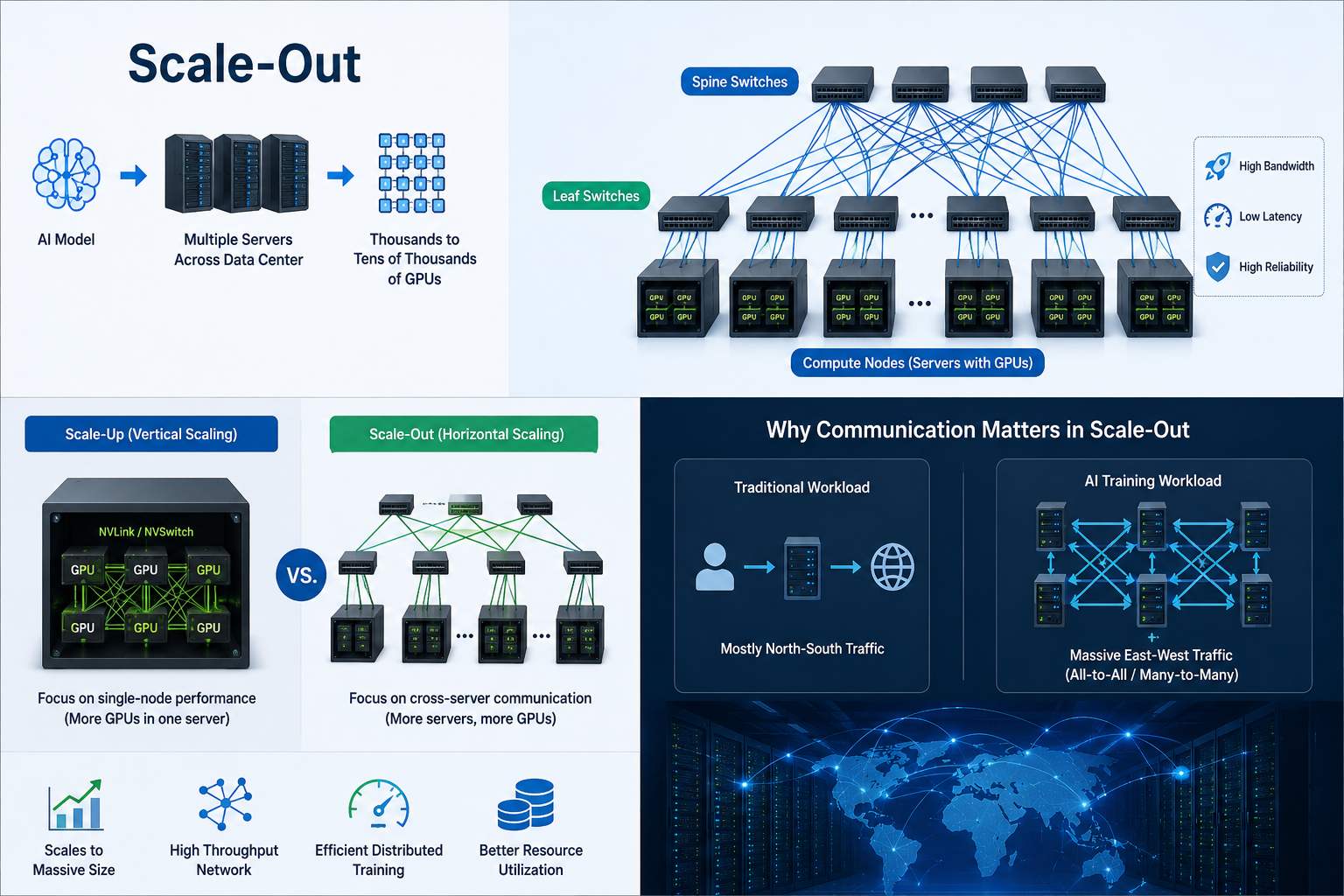
What is Scale-Out?
Scale-Out refers to expanding AI computing capacity by connecting multiple servers across a data center network, rather than relying on resources within a single machine. In modern AI infrastructure, this approach is essential for training large-scale models that require coordination across multiple nodes and thousands or even tens of thousands of GPUs.
Unlike Scale-Up, the core focus of Scale-Out is not single-node performance, but cross-server communication capability and network architecture design, because the efficiency of distributed training heavily depends on the speed of data exchange between nodes.
Core Enabling Technologies
• 800G High-Speed Ethernet
In Scale-Out architectures, 800G Ethernet switches serve as the core infrastructure of the data center network, carrying massive volumes of inter-server GPU communication traffic. As AI models continue to grow, the bandwidth demand between GPUs increases rapidly, and 800G networks provide the necessary bandwidth foundation to prevent the network from becoming a system bottleneck in large-scale distributed training.
• RoCE Technology
To achieve low-latency and high-throughput communication, AI clusters widely adopt RoCE (RDMA over Converged Ethernet). RoCE enables direct memory-to-memory data transfer between GPUs across different servers, bypassing the CPU and the operating system kernel path, thereby significantly reducing communication overhead.
This mechanism is particularly critical in distributed training operations such as gradient synchronization and parameter aggregation, where strong consistency is required. It effectively reduces communication latency and improves overall training efficiency.
• InfiniBand (IB)
InfiniBand is a high-performance networking architecture designed specifically for HPC and AI workloads. It provides more stable low latency and higher communication efficiency compared to Ethernet-based solutions, but its drawback is that it relies on a proprietary protocol ecosystem.
Leaf–Spine Network Topology
Scale-Out networks are typically built on a Leaf–Spine architecture to support non-blocking forwarding of large-scale east-west traffic.
- Leaf switches connect compute nodes (servers or GPU nodes)
- Spine switches provide high-bandwidth interconnectivity across the entire network
This design ensures highly symmetric network paths, making communication latency more predictable while delivering near-uniform bandwidth across the cluster. As a result, it is well-suited for large-scale AI training workloads.
AI Traffic Model as the Driving Force
From a workload perspective, Scale-Out architectures are driven by AI-specific traffic patterns, which are fundamentally different from traditional internet applications.
AI training typically generates large-scale All-to-All and Many-to-Many communication patterns, such as:
- Gradient All-Reduce: Each GPU computes its own gradients, but all results must be synchronized and averaged across all GPUs to keep the model consistent.
- Parameter Exchange: Instead of only sharing outputs, GPUs directly exchange parts of the model parameters.
- Tensor Parallelism: A large model is split across multiple GPUs, which jointly compute different parts of the same operation.
- MoE (Mixture-of-Experts) Routing Communication: Data is dynamically routed to different GPUs (experts), rather than following a fixed computation path.
These communication patterns place extremely high demands on network bandwidth, latency, and congestion control, making network performance a critical factor in overall training efficiency.
What is Scale-Across?
Scale-Across refers to an architecture that extends AI workloads beyond a single data center by connecting multiple compute clusters distributed across different data centers or cloud regions. Unlike Scale-Up, which focuses on scaling within a single node, and Scale-Out, which focuses on scaling within a single data center, Scale-Across builds a unified AI infrastructure composed of geographically distributed clusters.
In this architecture, each cluster operates its own GPU resources and training tasks, while collectively participating in a global AI training or inference workflow. As a result, Scale-Across is critical for frontier AI systems that require extremely large-scale compute capacity, high availability, and multi-region deployment capabilities.
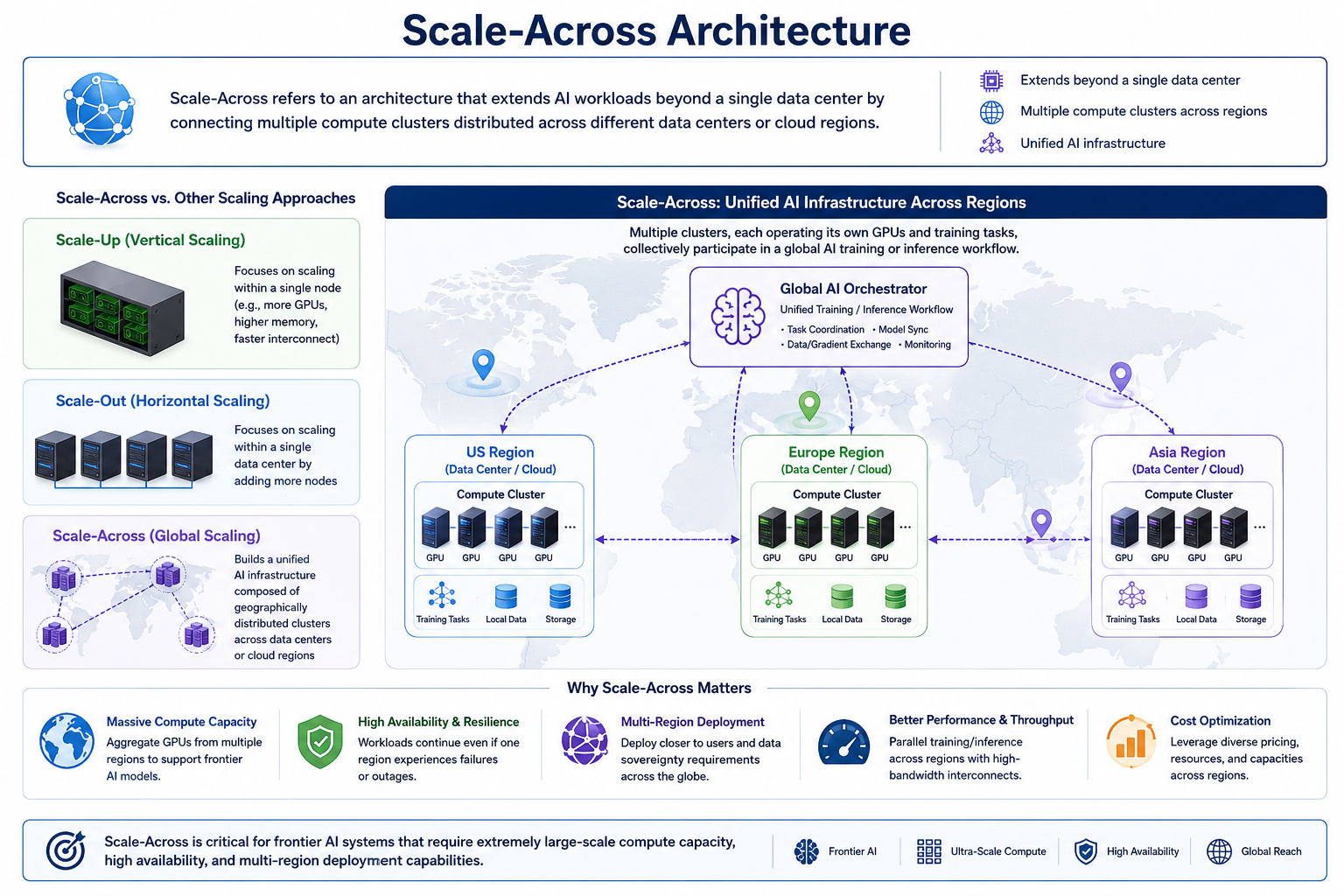
• Multi-Cluster AI Systems and Hybrid Interconnects
The foundation of Scale-Across lies in multi-cluster AI systems, which are connected through hybrid cloud and data center interconnect (Hybrid Cloud / DC Interconnect) technologies. These clusters may be distributed across on-premises data centers, public cloud regions, and edge environments, collectively forming a distributed computing network.
The interconnect layer typically relies on wide-area networks (WAN), dedicated private links, and high-bandwidth backbone networks. Compared to intra–data center networks, these cross-domain links have significantly higher latency and lower effective bandwidth, making communication constraints much more stringent.
Therefore, Scale-Across architectures often combine on-prem GPU clusters with cloud-based compute resources, dynamically scheduling workloads across regions based on performance, cost, and resource availability.
• Workload Orchestration
Workload orchestration is a key capability in Scale-Across architectures, responsible for coordinating AI task execution across multiple clusters and heterogeneous environments.
It includes distributed task scheduling, cross-region model partitioning, data locality management, and cross-cluster synchronization mechanisms. Due to the much higher latency of WAN compared to intra–data center communication, orchestration systems must carefully balance local compute efficiency with cross-cluster coordination to avoid overall performance degradation.
In practical systems, Scale-Across typically adopts a hierarchical orchestration approach: each data center independently optimizes local training efficiency, while a higher-level control plane manages global model updates and cross-cluster resource scheduling.
Scale-Across extends AI infrastructure beyond a single data center by connecting multiple compute clusters, enabling unified orchestration and coordination at a global scale.
However, this capability comes at the cost of significantly increased complexity in cross-cluster communication, synchronization, and system coordination, with the primary limitation being WAN latency and bandwidth constraints.
It should also be emphasized that Scale-Across capabilities are currently only partially implemented by a small number of hyperscalers such as Google, Microsoft/OpenAI, AWS, and Meta. The technology is still in an early stage, mainly used for multi-region resource scheduling and distributed deployment, rather than true cross–data center synchronous training.
Why AI Needs Three Types of Scaling
Modern AI systems cannot rely on a single scaling strategy, because performance bottlenecks arise in fundamentally different dimensions. As model sizes continue to grow, AI infrastructure has evolved into a multi-layer scaling system where Scale-Up, Scale-Out, and Scale-Across are all essential, jointly enabling efficient end-to-end computation and global deployment.
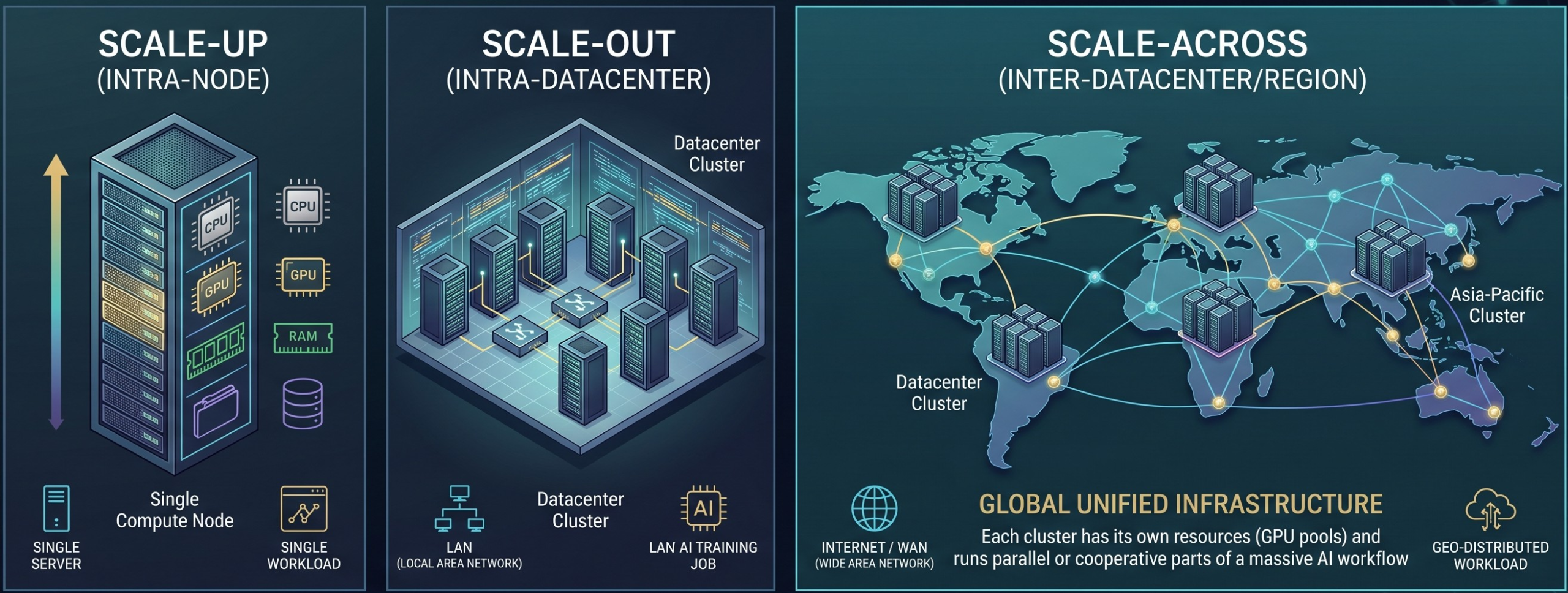
• Scale-Up: Improving Single-Node Performance
Scale-Up is the foundational layer of AI compute efficiency. It primarily increases the number of GPUs within a single compute node and leverages high-speed interconnect technologies such as NVLink and NVSwitch to boost performance.
The core goal of this layer is to minimize intra-node communication latency, allowing multiple GPUs to function as a unified compute engine. Without strong Scale-Up capability, even before distributed training begins, the single node itself becomes a performance bottleneck.
• Scale-Out: Expanding Training Scale
Scale-Out extends compute capacity by connecting multiple servers within a data center, making large-scale model training possible. It relies on high-speed networking technologies such as 800G Ethernet, RoCE, and InfiniBand to interconnect thousands of GPUs.
This layer primarily supports distributed training paradigms such as data parallelism, tensor parallelism, and pipeline parallelism. However, its efficiency is highly dependent on network bandwidth, latency, and congestion control capabilities.
• Scale-Across: Expanding System Boundaries
Scale-Across further extends AI infrastructure beyond a single data center by connecting multiple clusters across regions or cloud environments, enabling global-scale compute integration.
Unlike Scale-Up and Scale-Out, Scale-Across is primarily constrained by WAN latency and cross-region synchronization overhead. As a result, it is more commonly used for task distribution, multi-region deployment, and large-scale resource orchestration rather than high-frequency synchronous training.
| Dimension | Scale-Up | Scale-Out | Scale-Across |
| Scaling Scope | Within a single server / node | Across multiple servers within a data center | Across multiple data centers / cloud regions |
| Primary Goal | Maximize single-node compute performance | Expand cluster-level compute capacity | Build global-scale AI computing systems |
| Compute Unit | Multi-GPU within one server | Multi-server GPU clusters | Multi-cluster across regions / clouds |
| Communication Scope | GPU ↔ GPU (intra-node) | Server ↔ Server (intra–data center) | Data Center ↔ Data Center |
| Key Interconnect Technologies | NVLink / NVSwitch | 800G Ethernet / InfiniBand / RoCE | WAN / Cloud Interconnect / Backbone Networks |
| Typical Topology | NVSwitch fabric | Leaf-Spine architecture | Hierarchical / multi-region mesh |
| Latency Level | Nanoseconds to microseconds | Microseconds | Milliseconds |
| Bandwidth Characteristics | Extremely high (intra-node) | High (data center scale) | Relatively limited and variable |
| Main Bottlenecks | GPU interconnect limits | Network congestion / all-to-all traffic | WAN latency / synchronization overhead |
| AI Traffic Patterns | Tensor / pipeline / MoE (intra-node) | All-to-all / gradient synchronization | Parameter synchronization / distributed consistency |
| Optimization Focus | GPU interconnect efficiency | Network bandwidth + congestion control | Scheduling + synchronization + geo-latency optimization |
| Typical Use Cases | Single-node large model training | Large-scale distributed training | Global AI training / multi-cloud AI systems |
| Core Value | Extreme single-node performance | Scalable training across clusters | Global resource aggregation and coordination |
Summary
Together, these three scaling approaches form a complete modern AI infrastructure stack:
- Scale-Up: Optimizing single-node compute efficiency
- Scale-Out: Scaling large distributed training within a data center
- Scale-Across: Extending AI systems beyond global infrastructure boundaries
Only when all three work in coordination can AI systems achieve a balance between compute efficiency, scalability, and global deployment capability.