As AI clusters continue to grow and data center traffic patterns evolve, choosing the right network is no longer just a matter of “how much bandwidth.” It has become a systematic decision involving architecture design, scalability, and total cost of ownership (TCO). Not every network requires 800G—but in certain scenarios, scaling without 800G becomes extremely challenging. So the question is: Is 400G still enough, or is it time to move to 800G? The answer depends on your specific workload.
The Fundamental Differences Between 400G and 800G
On paper, 800G offers twice the bandwidth of 400G. But in real-world network deployments, the gap between the two goes far beyond just numbers.
Scalability and Cluster Size: The Decisive Factor
The 400G ecosystem is extremely mature and well-suited for small- to medium-scale deployments, such as AI clusters with hundreds of GPUs or general-purpose data centers. In contrast, 800G is designed for massive scale-out architectures, capable of supporting thousands or even tens of thousands of GPUs in parallel training environments. At this extreme scale, the network often becomes the primary bottleneck, directly determining overall training efficiency.
Flat Topology: Network Diameter’s Game-Changing Impact
As cluster size grows, network hierarchy can directly erode performance. Building large-scale 400G networks usually requires multi-tier Clos architectures, which inevitably increase physical hops and end-to-end latency.
With its ultra-high per-port throughput, 800G makes it possible to build much flatter network topologies. In AI environments dominated by east-west traffic (server-to-server communication), reducing network layers directly translates into meaningful efficiency gains. As clusters scale to thousands or even tens of thousands of GPUs, combining 800G with a flat topology—such as Dragonfly or Dragonfly+—delivers a clear performance and scalability advantage over traditional multi-tier Clos architectures.
| Spec | CX732Q-N · 400G | CX864E-N · 800G |
|---|---|---|
| Switching Capacity | 12.8 Tbps | 51.2 Tbps |
| Port Count | 32× 400G QSFP-DD | 64× 800G OSFP |
| Port-to-Port Latency | ~500 ns | ~560 ns |
| On-Chip Buffer | 70 MB | 200 MB |
| ASIC | Marvell Teralynx 7 | Marvell Teralynx 10 (5nm) |
| Form Factor | 1U | 2U |
| Max Power | ~550 W (typical) | ~2,200 W (max all-port) |
| RoCEv2 / RDMA | Yes | Yes |
| INT / Telemetry | Yes | Yes (BDC + HDC → Grafana) |
| SONiC NOS | AsterNOS (Enterprise SONiC) | AsterNOS (Enterprise SONiC) |
| UEC Compliance | Partial | Full (line-rate programmable) |
| Price (approx.) | ~$12,000 | ~$46,800 |
Compared to Broadcom’s Tomahawk 5 (which has a latency of approximately 800 nanoseconds), the 800G chip (Teralynx 10) exhibits 30% lower port-to-port latency. This performance gap is critical when running synchronous AllReduce across thousands of GPUs.
800G Solves a Scale Problem, Not a Cost Problem
While 800G delivers significantly higher per-port bandwidth and enables the possibility of flatter network topologies in AI deployments—thereby improving overall throughput efficiency—this does not mean it is more economical.
In scenarios where 800G is required (such as large-scale AI training clusters with tens of thousands of GPUs), higher bandwidth combined with fewer network layers can indeed provide better performance. However, this improvement in efficiency does not directly translate into cost savings.
From the current market perspective (taking SONiC-based open networking switches as an example):
400G SWITCHES
~$10,000
Typical market pricing
800G SWITCHES
~$40,000
Typical market pricing
A frequently overlooked reality is that the largest portion of network cost is often not the switches themselves, but the optical transceivers and cabling that connect them. Taking cost-effective short-reach SR4 modules as an example:
~$400
400G SR4 transceiver (typical)
~$750
800G SR4 transceiver (typical)
~87.5%
Transceiver cost premium for 800G
This means that while 800G theoretically doubles bandwidth, the per-port transceiver cost also nearly doubles. When scaling AI clusters to hundreds or thousands of ports, this near-100% premium quickly becomes a significant and often underestimated “hidden barrier.”
Therefore, even though 800G can reduce network layers through higher bandwidth and enable flatter architectures, its overall initial investment (CAPEX) remains significantly higher than 400G. At this stage, the primary value of 800G lies in supporting extreme scale and performance requirements, rather than reducing cost.
⚠ Hidden CAPEX Trap
At scale, optical transceiver costs routinely exceed the cost of the switches themselves. When someone shows you a 400G-to-800G TCO comparison, ask them what transceiver pricing they used. If they say “we’ll figure that out later,” that’s your red flag.
Match Your Network: 400G or 800G — Just Follow the Guide!
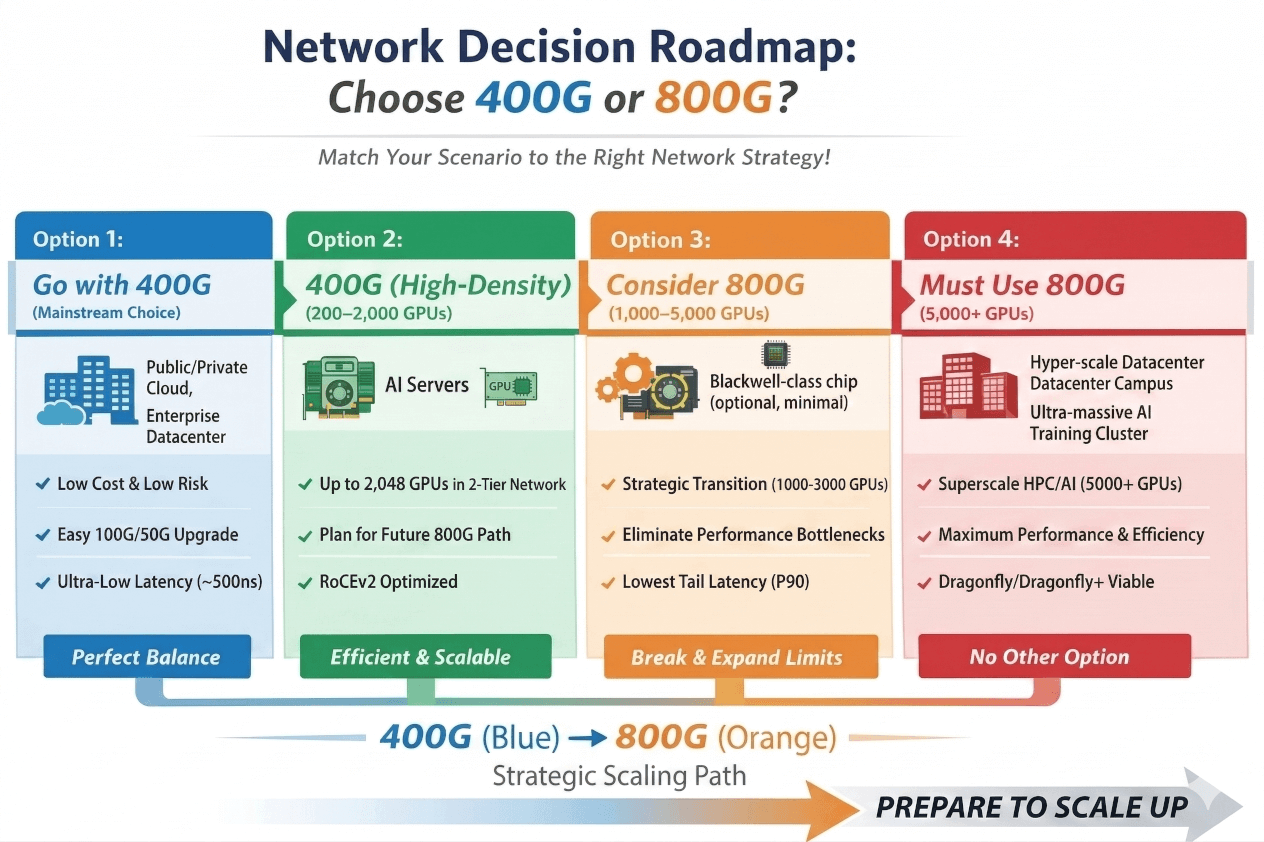
Scenario 01
Choose 400G
Traditional Cloud / Enterprise DC / CPU-Heavy Workloads
Mature ecosystem, low transceiver costs, zero retraining for your ops team. 100G/50G backward compatibility works seamlessly. ~500ns cut-through latency handles microservices and NVMe-oF without breaking a sweat. This is the no-regrets choice for general compute.
Scenario 02
Choose 400G (High-Density)
Medium-Scale AI · Hundreds to ~2,000 GPUs
Standard RoCE at 400G fully handles most training workloads short of frontier model scale. Key: use high-density 64-port 400G switches to stay in a flat two-tier topology. The moment you go three-tier at this scale, your cost and latency story collapses.
Scenario 03
Consider 800G
Strategic Crossover · 1,000–5,000 GPUs
Approaching the physical ceiling of 400G two-tier topology. If your AI servers are already shipping with 800G NICs (Blackwell, ConnectX-8), the network must keep up or GPUs will idle waiting on the fabric. Future-expanding to 3,000+ GPUs mid-lifecycle? Start with 800G now to avoid a painful architecture teardown.
Scenario 04
800G Is Non-Negotiable
Superscale AI / HPC · 5,000–10,000+ GPUs
At this scale on 400G, you’re looking at three or four-tier topologies, optical module counts that grow exponentially, and a single-point failure blast radius that will keep your ops team awake at night. 800G isn’t a nice-to-have — it’s the only architecture that keeps TCO rational at this tier.
Detailed Scenario Breakdown
Scenario 1: Go for 400G (Mainstream Optimal Choice)
If your network is a traditional public/private cloud upgrade, an enterprise data center, or a general-purpose CPU-centric computing environment, then 400G remains the best choice. 400G can smoothly interoperate with existing 100G/50G architectures, optical module costs are low, and operational teams have rich experience. Combined with the ultra-low latency characteristics of modern switching ASICs, 400G represents the best balance of performance, risk, and cost.
Scenario 2: Medium-Scale but Latency-Sensitive AI Clusters (Hundreds to ~2,000 GPUs)
For AI clusters of this scale, 400G is still the optimal choice in terms of cost-effectiveness and maturity, covering most training workloads. As long as the model is not extremely large (e.g., GPT-5 scale), a 400G network based on standard RoCE architecture fully meets bandwidth and latency requirements.
However, practical deployment requires attention to physical topology limits:
Pain point at 512 GPUs: With mainstream 32-port 400G switches, a standard two-layer non-converged Spine-Leaf topology can only support up to 512 GPUs. Beyond this, the network must evolve into a three-layer topology, which dramatically increases optical module and cabling requirements, as well as end-to-end latency and cabling complexity.
High-density 400G breakthrough: The industry is moving toward higher-density 64-port 400G switches. With 64-port devices, the two-layer non-lossless network ceiling rises to 2,048 GPUs—allowing enterprises to maintain a very flat two-layer network at nearly 2,000 GPUs.
Within this scale, 400G remains the most advantageous solution. Still, considering future uncertainty, it is recommended to reserve physical resources to smoothly evolve to 800G.
Scenario 3: Consider 800G (1,000–5,000 GPUs, Transitional & Breakthrough Zone)
From a physical topology perspective, even though high-density 64-port 400G switches can push the two-layer network limit to 2,048 GPUs, clusters with 1,000–5,000 GPUs enter the strategic crossover zone between 400G and 800G. At this point, upgrading to 800G is not just about total cluster size; it is a necessary move to break physical network bottlenecks:
Per-GPU bandwidth bottleneck (Scale-up): When training extremely large models with heavy synchronous communication (high AllReduce proportion), achieving minimal time-to-train is critical. If AI servers (e.g., nodes with next-gen Blackwell architecture) already standardize on 800G NICs (e.g., ConnectX-8) to solve per-node I/O bottlenecks, the network must also upgrade to 800G; otherwise, 400G networks will limit GPU utilization.
Forward-looking topology and two-layer defense (Scale-out): 2,048 GPUs are the absolute physical ceiling for a two-layer 400G network. If the current cluster has ~1,500 GPUs but plans to expand to 3,000–5,000 GPUs, sticking with 400G forces a complex three-layer (Super-Spine) topology, resulting in a second surge in optical module and cabling costs. Introducing 800G switches (with 51.2T switching chips) from the start doubles switching capacity and port density, allowing a two-layer flat network even at 5,000 GPUs and avoiding costly future architecture overhauls.
Scenario 4: Must Use 800G (5,000 to 10,000+ GPU Super-scale AI Clusters)
For clusters exceeding 5,000 GPUs, or for building hyperscale AI centers or HPC supercomputing clusters, 800G is no longer optional; it is essential to maintain cluster operation and manage TCO. At this extreme scale, using 400G faces both physical limits and business cost penalties:
Explosive optical module and cabling growth: At 5,000–10,000 GPUs, even the densest 400G switches require extremely complex three- or four-layer topologies (Spine-Leaf-Super-Spine). Optical module and AOC cable counts grow exponentially, often surpassing the cost of switches alone and dramatically increasing power consumption (PUE).
Blast radius & operational limits: Tens of thousands of 400G optical modules increase daily failure risk. Using 800G switches with higher port density drastically reduces the number of network layers and cables, minimizing the blast radius and protecting operational stability.
Critical GPU utilization: Large-scale training (>5,000 GPUs) with DP, TP, FSDP generates massive all-node communication. Even minor network tail latency or congestion from multi-layer networks can cause hundreds or thousands of expensive GPUs to idle. 800G networks, combined with lossless network mechanisms like ECN/PFC, provide sufficient “highway bandwidth” and low oversubscription, ensuring job completion time and ROI.
In short, for super-scale clusters of 5,000 to 10,000+ GPUs, 800G is not just “faster lanes”; it is the key to reducing network layers, maintaining stability and low latency, and maximizing investment efficiency.
Breaking the “Bandwidth-Only Myth”: The Three Hidden Determinants of True AI Network Performance
In real-world AI compute center network design, bandwidth is a fundamental factor—but it is by no means the sole measure of performance. What truly determines GPU cluster training efficiency (Job Completion Time, JCT) and ROI are three core elements:
1. Buffering and Congestion Control — The Physical Shield Against Microbursts
AI scenarios with heavy synchronous communication are prone to sudden Microbursts or Incast traffic spikes. If a switch’s buffer is exceeded, or if congestion control mechanisms like ECN/PFC respond too slowly, even massive bandwidth becomes useless, causing packet loss and costly GPU idle cycles.
Asteraix’s solution: Our switches are designed with extremely high anti-congestion headroom at the hardware level. Its 400G platform offers up to 70 MB of intelligent buffer, while the 800G platform reaches an astonishing 200 MB of ultra-deep on-chip cache—far exceeding competitors. Combined with optimized lossless networking strategies, this deep hardware buffering perfectly absorbs extreme traffic spikes, ensuring a smooth network under heavy load.
2. Ultra-Low Nanosecond Latency — Breaking the Myth That High Bandwidth Means High Delay
Latency is the lifeline of large-scale parallel training. Some traditional 800G devices, due to complex internal architectures or excessive network hops, introduce uncontrollable delays, resulting in “high bandwidth but slower execution.”
The solution: The CX732Q-N 400G switch achieves industry-leading 500 ns latency, while the flagship CX864E 800G reduces it further to 560 ns. In direct competition with traditional AI network leader InfiniBand, 800G solution delivered exceptional outperformance: P90 tail latency dropped by 20.4%, and overall throughput (TCR) increased by 27.5%. This means that in real-world large-model training, We not only outperforms IB in speed but also provides more stability.
3. Green Efficiency and Long-Term OPEX — The Foundation of Compute Centers
Higher bandwidth usually comes with soaring per-port power consumption, challenging data center cooling limits and driving long-term operating costs (OPEX). Choosing a network isn’t just about peak performance—it’s about sustainable efficiency over time.
The solution: The CX864E-N 800G switch sets a benchmark in power efficiency. In extreme testing with 64 fully loaded ports and 2×SR4 800G optical modules per port, total power consumption remains only 2,200 W. This dramatically alleviates PUE pressure in ten-thousand-GPU compute centers and saves enterprises substantial hidden costs over the long term.
The Two Products Worth Looking At
Asteraix offers the full CX-N lineup, but if you’re choosing between 400G and 800G today, these are the two flagship data center switches to evaluate:
400G Data Center Switch
CX732Q-N
32× 400G QSFP-DD · Marvell Teralynx · Enterprise SONiC
Total Capacity
12.8 Tbps
Latency
~500 ns
Buffer
70 MB
Form Factor
1U
RDMA / RoCEv2
Yes
NOS
AsterNOS (SONiC)
800G Data Center Switch
CX864E-N
64× 800G OSFP · Marvell Teralynx 10 · Enterprise SONiC
Total Capacity
51.2 Tbps
Latency
~560 ns
Buffer
200 MB
Form Factor
2U
RDMA / RoCEv2
Yes
NOS
AsterNOS (SONiC)
Both switches ship with AsterNOS pre-installed — enterprise SONiC distribution. It includes the best available SAI support, BGP-EVPN, VXLAN (up to 4K groups), 256-way ECMP, gNMI/REST/NETCONF management interfaces. You’re not getting a bare-metal curiosity that needs a month of NOS integration work — it’s production-ready out of the box.
ℹ Also Available
If you’re looking for a 400G switch based on Marvell Falcon (rather than Teralynx) for more cost-sensitive deployments or campus aggregation roles, check out the CX732Q-N Falcon variant — same port count, Supports PTP with 10-nanosecond precision, features larger routing tables and VRF capabilities and so on.
Conclusion
In essence, the choice between 400G and 800G is not a matter of “old vs. new,” but an engineering decision that should be grounded in real business needs. 400G represents the present—mature, stable, and cost-effective—making it the optimal choice for most small- to mid-sized AI clusters. In contrast, 800G represents the future, providing the necessary headroom for larger-scale and more demanding training workloads.
The key is not to blindly pursue higher bandwidth, but to ensure that your network aligns with your actual compute scale, traffic patterns, and future growth plans. There is no universally “best” speed—only the one that best fits your workload. Understanding your application comes before choosing your bandwidth; that is the true starting point for building an efficient AI network.

