As enterprise network workloads continue to scale, application scenarios such as high-definition cross-domain video conferencing, real-time financial data feeds, and large-scale IoT firmware distribution impose increasingly stringent demands on concurrent network transmission capacity. The traditional Unicast model exhibits an O(N) linear complexity bottleneck when handling one-to-many high-concurrency traffic, resulting in redundant egress bandwidth consumption and gateway resource exhaustion. This paper systematically examines the foundational principles of IP Multicast technology, with particular emphasis on the implementation mechanisms of AsterNOS’s decoupled heterogeneous architecture, which combines a SONiC control plane with a VPP data plane. Key areas of analysis include IGMPv3-based endpoint subscription management, the optimization of routing from Shared Tree (RPT) to Shortest Path Tree (SPT) under PIM Sparse Mode, and the fundamental reduction of CPU and memory overhead achieved through VPP Zero-Copy technology. The findings demonstrate that this architecture elevates multicast distribution efficiency from O(N) to O(1), and that its deep BGP integration combined with ECMP load balancing enables millisecond-level fault convergence, providing a highly available and resource-efficient traffic distribution solution for modern enterprise egress gateways.
Introduction: The Architectural Limitations of the Traditional Unicast Model
As enterprise digital transformation advances, network traffic patterns have progressively shifted from traditional client-server point-to-point communication toward high-concurrency distribution scenarios characterized by a single source transmitting to multiple simultaneous receivers. Against this backdrop, the inherent architectural deficiencies of the Unicast model have become increasingly apparent, emerging as a core bottleneck constraining the scalability of large-scale concurrent workloads.
Under the Unicast paradigm, the data source is required to maintain an independent point-to-point transmission session for each receiving node, physically replicating the data payload and dispatching an equivalent number of copies to each destination endpoint. This mechanism causes network resource consumption to scale with O(N) linear complexity: as the number of receiving nodes N increases, the egress link bandwidth, source server NIC throughput, and intermediate node forwarding resources all grow proportionally.
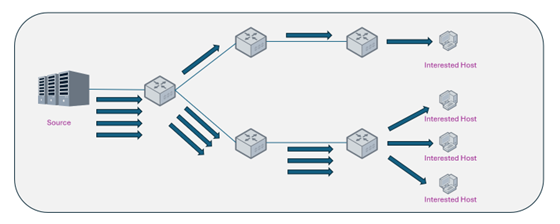
Consider a representative enterprise scenario: a multinational corporate data center distributes an identical high-definition video stream to a large number of terminals across global branch offices. Under a unicast architecture, the core egress gateway must carry redundant traffic proportional to the total number of receiving endpoints. At scale, this architecture precipitates two categories of critical engineering problems:
- Network Congestion: The high volume of duplicated packets occupies a disproportionate share of backbone link bandwidth, directly squeezing the available bandwidth for mission-critical applications such as ERP systems and SIP voice communications, thereby degrading overall network Quality of Service (QoS).
- Resource Exhaustion: The I/O throughput overhead on the source server NIC and the CPU forwarding load on intermediate gateway devices scale linearly with concurrent session count, creating significant risk of resource exhaustion and service interruption under high-concurrency peak conditions.
The root cause of these issues lies in the Unicast architecture’s placement of data replication responsibility at the source and egress devices, rather than distributing it across the network transmission path. IP Multicast technology addresses this bottleneck at the architectural level by fundamentally restructuring the location and mechanism of traffic replication.
2. Principles of IP Multicast: Achieving O(1) Forwarding Efficiency
IP Multicast technology resolves the scalability limitations of Unicast by transferring the responsibility for data replication from source-end servers to the underlying network infrastructure, specifically to routers and switches distributed throughout the transmission path.
Under the multicast mechanism, the data source transmits only a single stream copy to a designated Class D IP address. Network devices perform packet replication exclusively at network branching points where active subscribers exist, as dictated by the distribution tree topology established through multicast routing protocols. This mechanism reduces source-end and backbone link bandwidth overhead from O(N) to O(1): regardless of how the number of receiving endpoints scales, the total traffic volume carried by the source and core links remains constant. This fundamentally resolves the linear scaling bottleneck of Unicast architecture and substantially improves overall WAN link utilization.
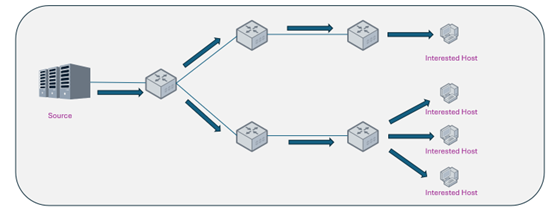
3. Construction of Multicast Distribution Trees in AsterNOS
AsterNOS provides full support for the industry-standard multicast protocol stack, achieving efficient path establishment and state maintenance through the coordinated operation of IGMP on the endpoint side and PIM protocols on the network side.
3.1 Endpoint Subscription Management: The IGMPv3 Source Filtering Mechanism
AsterNOS recommends deploying IGMPv3 at the access layer. Compared to the any-source reception model (*, G) used in earlier protocol versions, IGMPv3 introduces precise source address filtering capabilities, enabling the (S, G) source-specific multicast subscription model. Endpoints may not only subscribe to specific multicast group channels but may also explicitly declare trusted sender source addresses.
This mechanism provides a security-layer defense against unauthorized traffic injection, while simultaneously establishing the protocol foundation necessary for constructing efficient PIM-SSM (Protocol Independent Multicast – Source Specific Multicast) architectures.
3.2 Route Optimization: Transitioning from Shared Tree (RPT) to Shortest Path Tree (SPT)
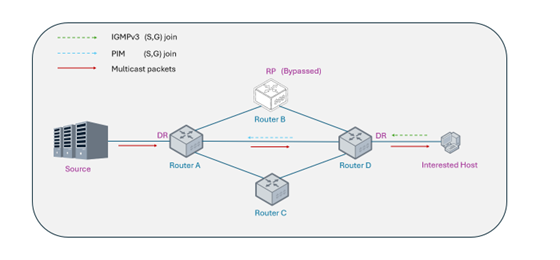
In a standard PIM-SM (Sparse Mode) deployment, the network initially lacks information regarding the location of the multicast source. AsterNOS employs the industry-standard two-phase tree construction mechanism to achieve dynamic convergence from a suboptimal path to an optimal forwarding path.
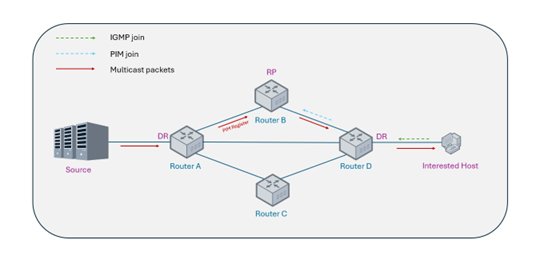
Phase 1: Construction of the Shared Tree (Rendezvous Point Tree, RPT)
The receiver-side gateway transmits a (*, G) Join message toward a pre-configured Rendezvous Point (RP) within the network, establishing a downstream reception path. Concurrently, the multicast source registers with the RP and begins forwarding data through it. This phase establishes the initial shared distribution path, enabling receivers to begin receiving multicast data even before the source location is definitively known.
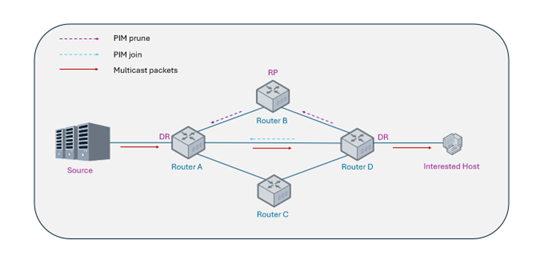
Phase 2: SPT Switchover and State Pruning
To avoid suboptimal routing and the single-point bottleneck inherent in RP-centric forwarding, AsterNOS immediately initiates an SPT switchover upon receiving the first multicast data packet. Once the actual multicast source IP address is resolved, the system dispatches an (S, G) Join request directly toward the source, referencing the unicast routing table, to establish the Shortest Path Tree (SPT). Upon SPT establishment, AsterNOS automatically transmits Prune messages to sever the redundant path via the RP, thereby optimizing data distribution efficiency across the core backbone network.
3.3 Advanced Evolution: PIM-SSM for Source-Specific Multicast
For business scenarios with fixed and known source addresses, such as internal streaming media from dedicated sources or financial market data distribution feeds, AsterNOS supports the streamlined PIM-SSM operational mode. Operating in conjunction with IGMPv3, this mode eliminates the requirement to configure and maintain complex RP nodes within the network.
Receiving endpoints may directly initiate (S, G) Join requests, bypassing the state negotiation phase associated with shared tree construction and establishing the Shortest Path Tree to a specific multicast source directly. This achieves the maximum possible simplification of network structure and operational efficiency.
4. Core Architectural Advantages of AsterNOS: The SONiC and VPP Synergy
While standard multicast protocol implementations have become largely homogeneous across the industry, the core competitive advantage of AsterNOS-VPP in ultra-large-scale multicast scenarios lies in its deeply optimized, decoupled software-hardware architecture, which combines a SONiC control plane with a VPP data plane. This architectural design fundamentally reconstructs the system’s computational and memory overhead model.
4.1 Control Plane: Agile Routing Management via Containerized SONiC
AsterNOS fully leverages the open architecture of the SONiC operating system to deploy complex multicast control protocols, including PIM and IGMP daemons within FRRouting, in a containerized manner. The control plane focuses exclusively on processing PIM state machines and loop-prevention calculations; upon generating optimal (S, G) forwarding entries, it efficiently programs them into the data plane via internal APIs.
The deep isolation between the control plane and data plane ensures that under conditions of complex network flapping, protocol computation processes do not interfere with underlying data forwarding operations, thereby enhancing the overall stability and reliability of the system.
4.2 Data Plane: The Fundamental Reduction of CPU Load via VPP Zero-Copy Technology
When executing multicast distribution, traditional software routers based on kernel network stacks must perform N complete physical copies of the entire packet payload in memory, one for each of N egress interfaces. This mechanism is the primary cause of CPU overload and memory bandwidth exhaustion in high-concurrency multicast deployments.
AsterNOS relies on the VPP (Vector Packet Processing) architecture to fundamentally reconstruct this resource consumption model through the following mechanisms:
- Zero-Copy Design: When identical multicast streams must be dispatched concurrently to multiple egress interfaces, VPP avoids repetitive physical copying of the large data payload region. The system clones only minimal packet metadata (containing the L2 header rewrite information required by each egress interface) for each distinct output port, and atomically increments the Reference Count of the shared memory region where the packet resides.
- Memory I/O Offloading: During the final transmission phase, the NIC of each egress port reads the identical physical memory block based on its respective metadata to complete packet dispatch. This mechanism drastically reduces system memory bandwidth utilization and CPU copy overhead, enabling commodity compute platforms to handle the concurrency demands of large-scale multicast sessions with ease.
4.3 BGP and ECMP Integration: Guaranteeing Multicast High Availability
- High-Availability RPF Integration: The AsterNOS multicast engine is deeply integrated with the underlying BGP routing table. When topology changes occur on cross-domain WAN links, the RPF (Reverse Path Forwarding) validation mechanism responds immediately, triggering dynamic reconstruction of the multicast distribution tree and enhancing the disaster recovery capability of core business services, achieving millisecond-level fault convergence.
- ECMP Traffic Load Balancing: Transcending the single-path forwarding constraints of traditional multicast, AsterNOS supports Equal-Cost Multi-Path (ECMP) hash-based scheduling derived from (S, G) session states. This effectively distributes different multicast streams across multiple available backbone links, preventing single-point link congestion and improving overall link utilization.
5. Technical Comparison and Deployment Benefits
| Dimension | Traditional Multicast Architecture | AsterNOS Multicast (SONiC+VPP) |
| System Architecture | Monolithic OS or hardware-coupled design | Decoupled: Containerized SONiC + VPP data plane |
| Replication Overhead | O(N) linear memory copies, scaling proportionally with node count | O(1) efficiency via VPP Zero-Copy reference counting |
| Route Convergence | Standard convergence times, hardware-dependent | Millisecond-level RPF updates via deep BGP integration |
| Traffic Engineering | Typically constrained to a single network path | ECMP load balancing based on (S,G) session states |
| SSM Deployment | May require complex legacy protocol support | Natively streamlined via IGMPv3 edge enforcement |
5.1 Deployment Use Cases
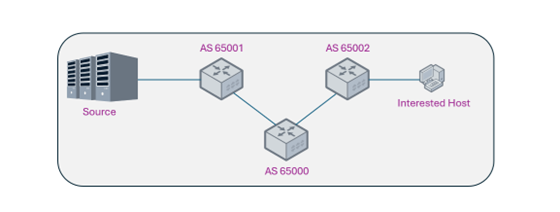
Use Case 1: Cross-Domain High-Availability Multicast Architecture
Deployment Benefit: Establish highly available global multicast distribution trees spanning multiple BGP Autonomous Systems, ensuring business continuity across organizational domains.
Implementation Approach: Designate a Spine node as the core Rendezvous Point (RP) and inject physical link routes via BGP to ensure network-wide RPF validation consistency, guaranteeing millisecond-level recovery during WAN link flapping events.
Reference configuration:
#Spine (RP Layer): BGP Underlay & RP Designation
sonic(config)# router bgp 65000
sonic(config-router-af)# network <Underlay_Subnet>
sonic(config-router-af)# exit
sonic(config)# ip pim rp <RP_IP_Address> <Multicast_Group_Range>
# Source Leaf Node: Trigger initial registration
sonic(config)# unknown-multicast trap
Use Case 2: Streamlined PIM-SSM Distribution (Topology Optimization)
Deployment Benefit: Eliminate transit bottlenecks and simplify network architecture by bypassing Rendezvous Points for known fixed-source traffic flows.
Implementation Approach: Applicable to financial market data feed distribution or dedicated IPTV network scenarios. IGMPv3 is leveraged to construct a Shortest Path Tree (SPT) directly from the receiver to the fixed data source, achieving maximum network simplicity and optimal forwarding efficiency.
Reference configuration:
# Network-wide: Remove forced RP transit paths to streamline topology
sonic(config)# no ip pim rp
# Receiver Leaf: Enforce Source Filtering to enable PIM-SSM sonic(config)# interface ethernet X
sonic(config-if)# ip igmp version 3
6. Conclusion
In the construction of modern enterprise backbone networks, the simple aggregation of additional physical bandwidth is no longer sufficient to address the demands of complex concurrent workloads. Architectural innovation represents the fundamental pathway to resolving network scalability bottlenecks.
By organically integrating the agile protocol control capabilities of SONiC with the high-performance Zero-Copy forwarding mechanism of the VPP data plane, and augmenting this with millisecond-level fault convergence achieved through deep BGP integration, AsterNOS endows IP Multicast technology with substantive new engineering value.
Whether constructing a highly resilient BGP multicast architecture or implementing a streamlined and performant SSM solution, AsterNOS, by virtue of its technical advantages in underlying resource optimization, enables enterprises to simultaneously guarantee high-concurrency scalability while achieving meaningful reductions in network infrastructure capital and operational expenditure.