




800GbE AI Switch with 64x OSFP Ports, 51.2Tbps, Enterprise SONiC Ready
$46,800.00
- 51.2 Tbps in 2RU: Supports 64×800G, 128×400G, or 512×100G.
- Fastest Switch in Class: Sub-560 ns port-to-port latency.
- Massive Buffering: 200MB+ on-chip buffer optimized for RoCE.
- Precision Timing: 10 ns PTP & SyncE for AI synchronization.
- Advanced Telemetry: INT for real-time packet visibility & congestion control.
- Efficient Power: Max 2200W TDP under full load (64×800G SR8).
- Open AsterNOS: SONiC-based with top-tier SAI support.
- Fully Compatible: Works with all major GPUs & SmartNICs.
- UEC Ready: Line-rate programmable for future standards.
- 800G ZR/ZR+ optical module: Support metro and long-haul connectivity.
Note: Prices are exclusive of customs duties, import taxes, and VAT. Any additional charges imposed by your country are the buyer's responsibility.
Designed for AI inference/training, high-performance computing(HPC), and cloud computing/ storage, the Asterfusion CX864E-N AI Switch delivers 51.2 Tbps switching capacity in a compact 2RU form factor with 64x800G OSFP ports. Built on Marvell Teralynx 10 ASIC, this 800G switch supports ultra-low latency (<560ns), up to 28.7 Bpps of L2/L3 full wire-speed forwarding, and 200+ MB of on-chip buffer. Asterfusion CX864E-N Open Ultra Ethernet Switch is the premier choice for data centers in the AI era.
Networking
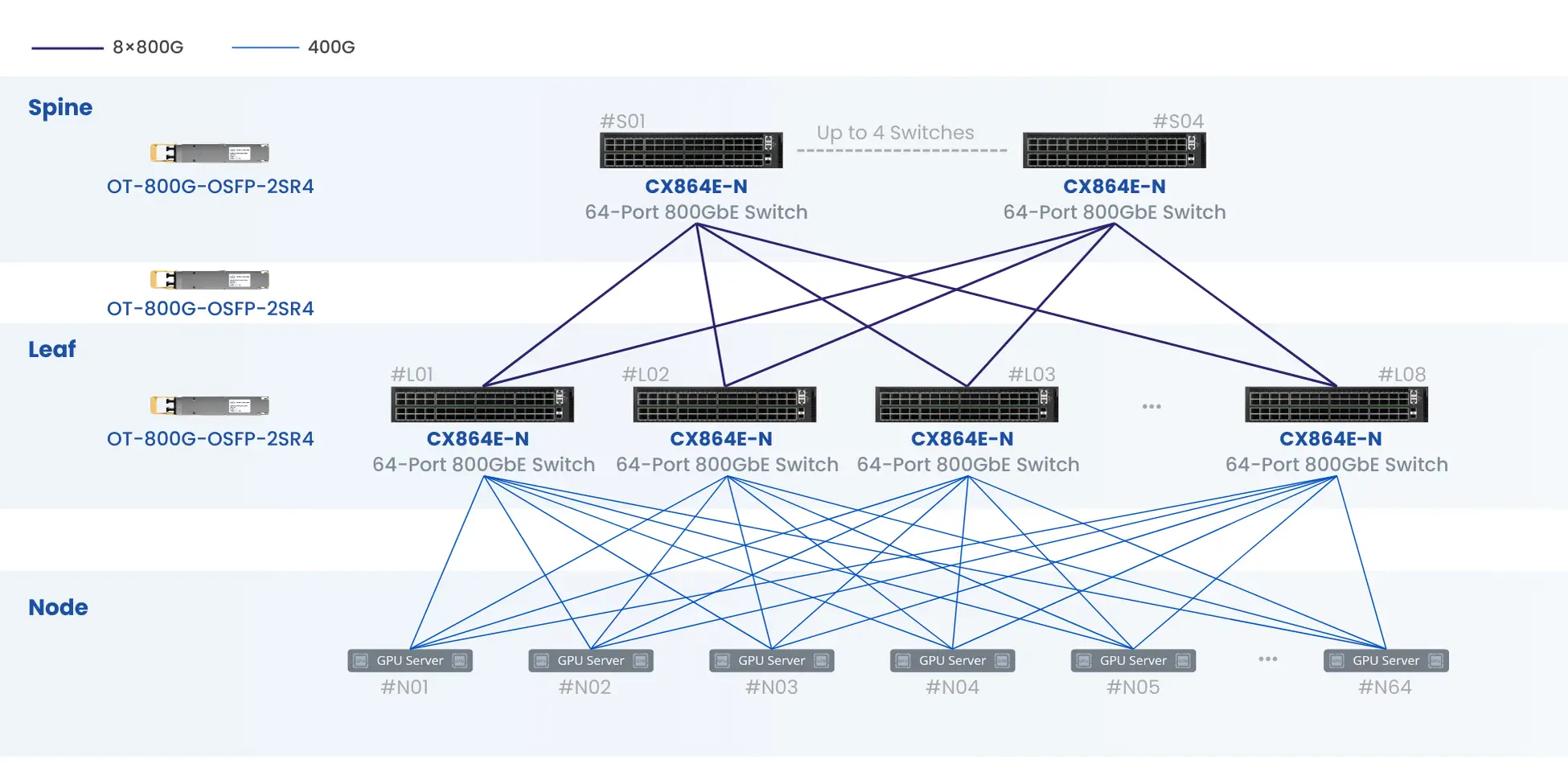
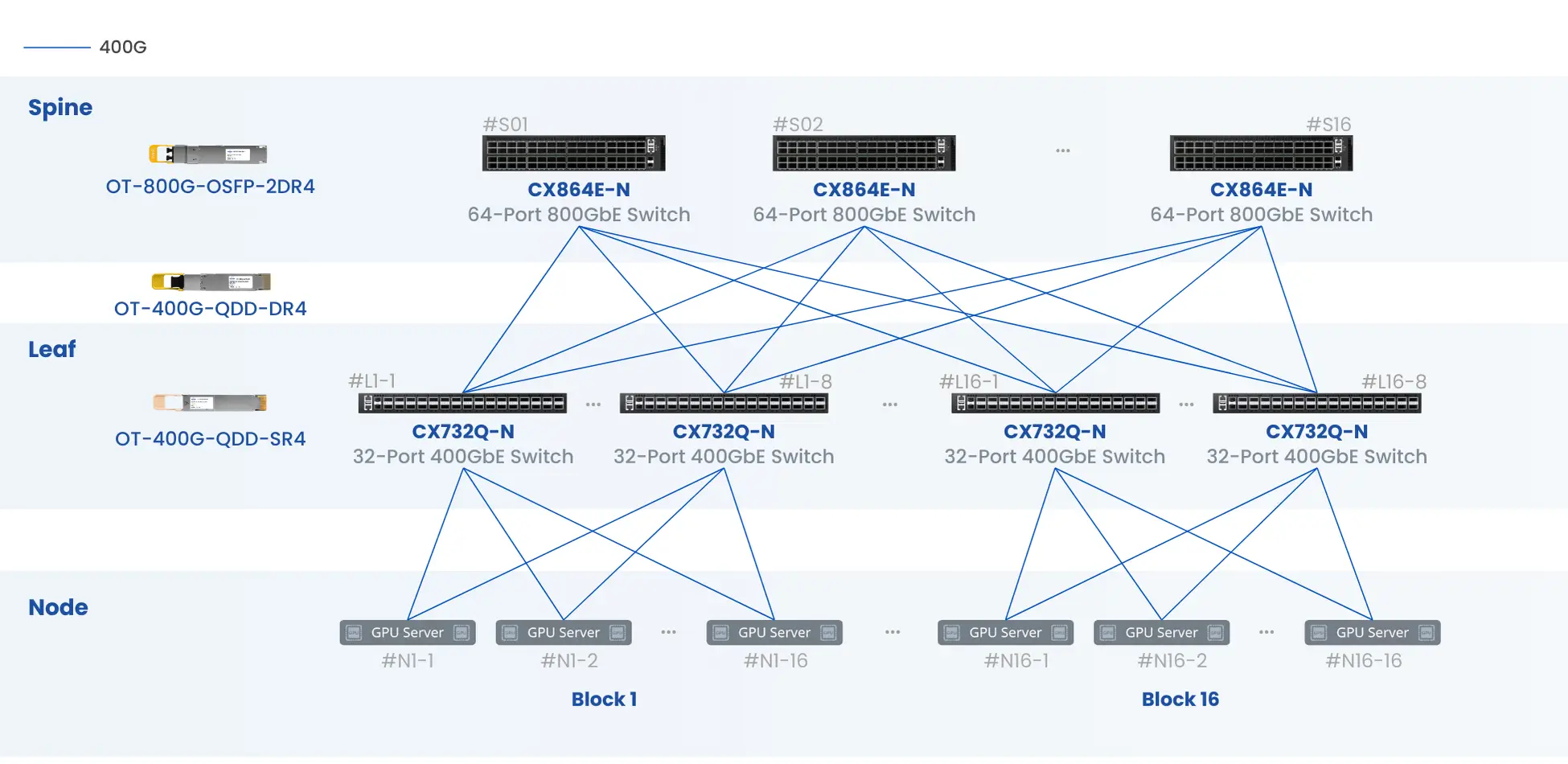
◼ 8 x CX864E-N supports 512 GPUs interconnection with 400G per port speed
◼ 192 X CX864E-N supports 8192 GPUs interconnection with 400G per port speed
◼ 192 X CX864E-N supports 128K ML/AI nodes interconnection with 100G per port speed
◼ Support for all leading collective communication libraries, including NCCL, RCCL, oneCCL, BCL, MPI, and Gloo
◼ Optimize collective operations (Allreduce, Allgather, All-to-all, Broadcast) with built-in multicast
◼ Support various network topologies, including spine-leaf, fat-tree, dragonfly, butterfly, 3D mesh/torus, hyper-x and hypercube
Specification
Rack & Physical
Dimension (HxWxD) 87×440×660mm
Airflow Front to Rear
Rack Space 2U
Data Plane Ports
Fixed Interfaces
(64) 800GbE OSFP
(2) 10GbE SFP+
800GbE Port Breakout Support (via splitter)
(128) 400GbE OSFP
(256) 200GbE QSFP56
(512) 100GbE QSFP28
Switch Core
Switch ASIC Marvell Teralynx 10
Switching Capacity 51.2Tbps
Packet Buffer 200MB
Forwarding Rate 28.7Bpps
Management & Control
Management Ports
(1) USB2.0
(1) Console RJ45
(1) MGMT RJ45
Control and Management CPU
(CPU) Intel Xeon 4/8-core
(RAM) 32GB SODIMM
(SSD) 256GB M.2 SATA/NVME
Address & Routing Entries
Mac Addr. Entries 44K
ARP Entries 36K
IPv4 Prefix Routes 72K
IPv6 Prefix Routes 36K
Power & Cooling
Power Module (1+1) Hot-pluggable
FAN Modules (3+1) Hot-pluggable
Input Range 200~240V AC / 200~320V HVDC
Max Power Consumption 2200W
Operating Environment
Op. Temperature 0~40℃ (32 to 104℉)
Op. Humidity 10%~90% (non-condensing)
Optimized Software for Advanced Workloads-AsterNOS
Pre-installed with Enterprise SONiC, the CX864E packs cutting-edge features like RoCEv2 and EVPN multihoming, delivering lightning-fast forwarding and massive packet buffers for unmatched performance. Fully UEC-compliant, it offers rich open APIs to seamlessly integrate into diverse data center and HPC ecosystems. As a vendor-neutral platform, it effortlessly supports heterogeneous GPUs and network cards from multiple manufacturers. By combining industry-leading low latency with expansive packet buffering, the CX864E sets the gold standard for next-generation AI-era data centers.
Lossless Network
Advanced Congestion Control
Benefit from rich QoS features including ECN, PFC, DCBX, QCN, DCQCN, and DCTCP for large-scale RDMA deployments.
Zero packet loss
ROCEv2 ensures microsecond-level low latency, high throughput, and near-zero packet loss, ushering in an AI-driven network performance and reliability era.
In-band Network Telemetry (INT)
Monitor packet delays, drops, and path traversal for advanced congestion control algorithms.
High-Reliability Network
Robust Load Balancing & Redundancy
Up to 8192-way equal-cost multi-path (ECMP) routing.
Seamless Connectivity
BGP multi-homing for multiple server connections with automatic load balancing and failover.
Active/Active Multipathing
Multi-chassis link aggregation group (MC-LAG) for superior L2 multipathing.
Rapid Failover
BFD for BGP and OSPF in just 50ms.
Ultra Low Latency Network
Unmatched Speed
Featuring Marvell Teralynx10 silicon, the world’s fastest switch, with port-to-port latency under 560ns for 800GE ports. Perfect for latency-sensitive applications like AI/ML, HPC, and NVME.
Enhanced Performance
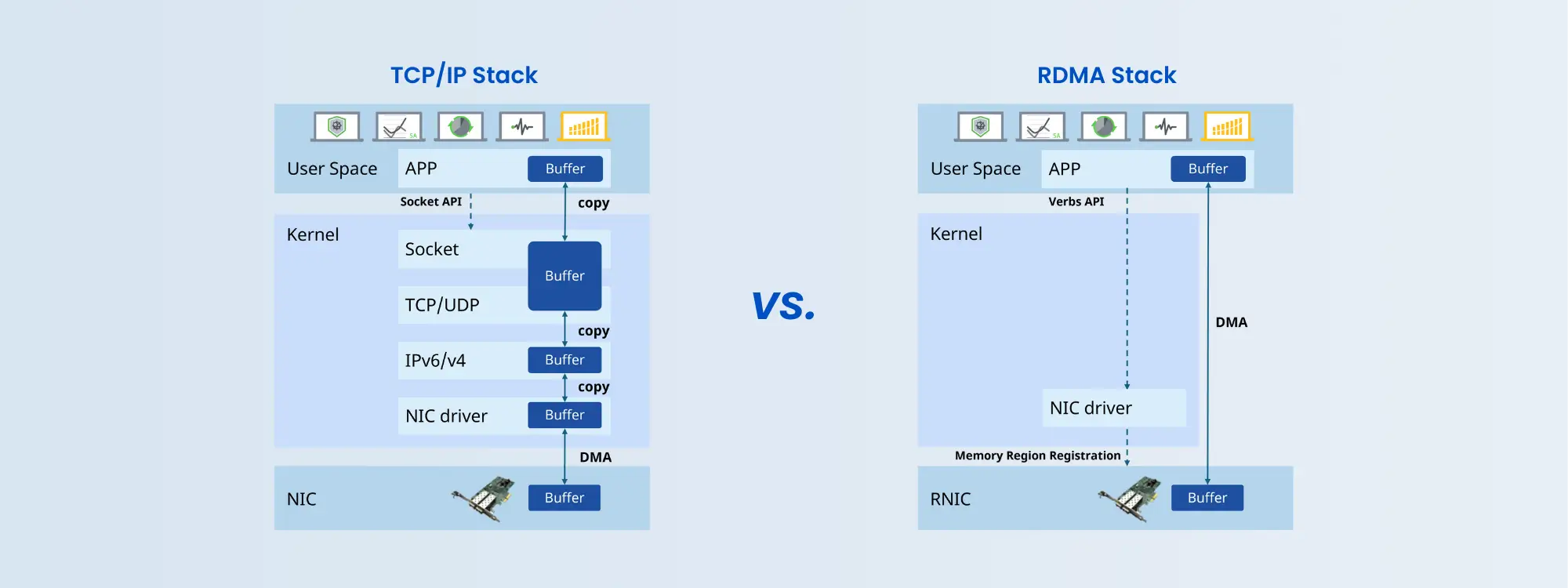
RDMA enables direct memory access, improving latency performance to a microsecond level.
Automated O&M Network
Effortless Operation
Integrated with Python and Ansible to support automated operations and maintenance.
Zero-Touch Provisioning (ZTP)
Automatically obtain and load deployment files, simplifying device setup.
Open Network
Open Enterprise SONiC Distribution
AsterNOS provides the best SAI support, ensuring robust and reliable performance.
Future-Proof
Line-rate programmability to support evolving UEC (Ultra Ethernet Consortium) standards.
Time-Sensitive Network
Precise Synchronization
Achieve 10ns PTP and SyncE performance, essential for synchronized AI parallel computing.
Connectivity solution
Summarize the advantages of CX864E-N in one sentence
Asterfusion’s 64×800G OSPF AI Switch
Ultra – Fast Ports
Comes with 64×800G ports, enabling lightning-quick data transfer to support AI-powered tasks and data-heavy operations.
AI – Driven Routing
Merges OSFP for effective routing with AI to boost network efficiency, automate processes, and foresee network hiccups.
64×800G OSPF AI Switch Documentation
Product Assurance & Logistics
Warranty & Support
Quality Certifications




Delivery Time
Our standard products are typically shipped within one week (business days).
For custom products, please contact customer service to inquire about the specific delivery time.
Frequently Asked Questions
560 ns
> 96.8%
< 2 μs
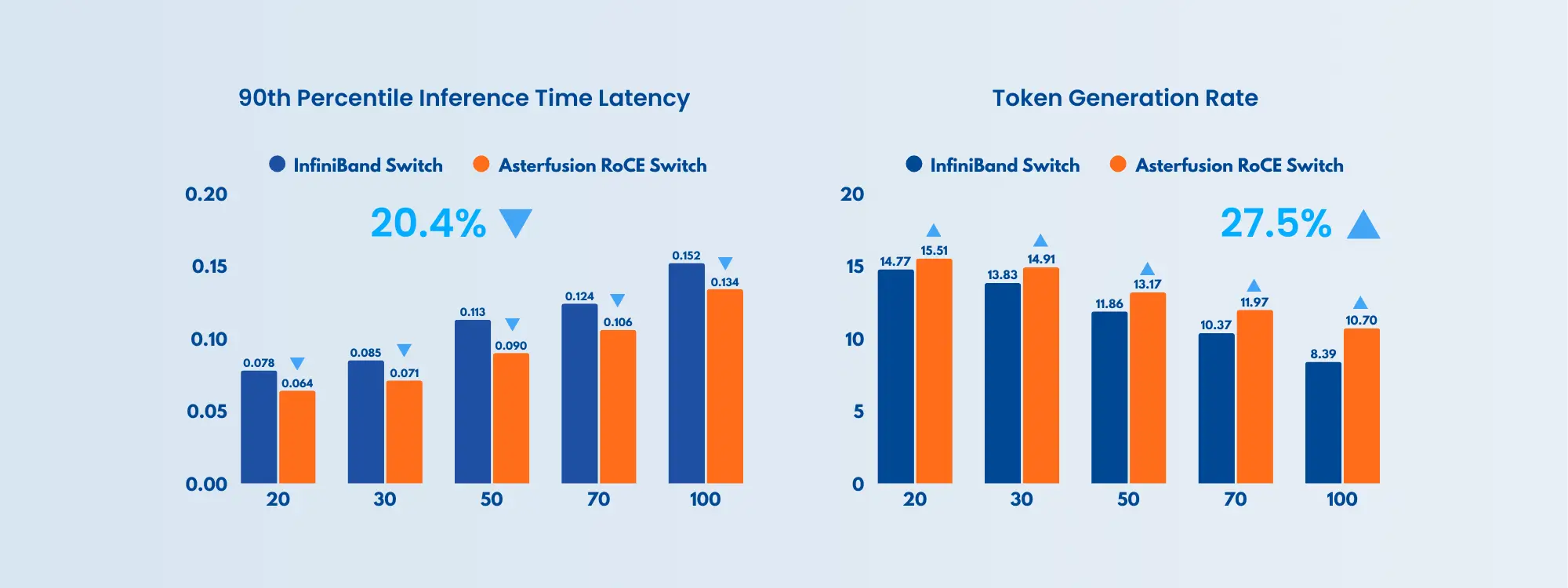
↓ 5% vs. IB
↑ 27.5% vs. IB
Advanced Hardware Features
Engineered for scalability, efficiency, and always-on reliability.
Marvell Teralynx 10 Inside: Unleash Industry-Leading Performance & Ultra-Low Latency
With Marvell Teralynx 10 at its core, Asterfusion 800G switches achieve blazing-fast sub-560ns latency—perfect for AI/ML, HPC, and NVMe where speed drives results.

Redundant Power Supplies & Smart Fans

Boasting 64×800GbE and 2×10GbE ports, the device supports interface splitting via breakout cables, which helps enhance the efficiency of network resource usage and accommodate diverse application scenarios.
The dual 1+1 hot-pluggable power supplies ensure continuous operation by allowing replacement without system shutdown. Equipped with 3+1 hot-pluggable fan modules, the system delivers reliable cooling performance to maintain stability and efficiency under demanding workloads.

Full RoCEv2 Support for Ultra-Low Latency & Lossless Networking
Asterfusion 800G switches deliver full RoCEv2 support with ultra-low latency and near-zero CPU overhead. Combined with PFC and ECN for advanced congestion control, it enables a true lossless network.
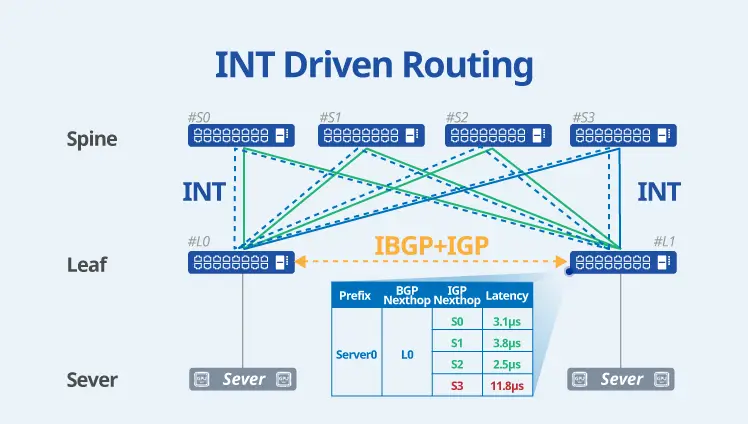
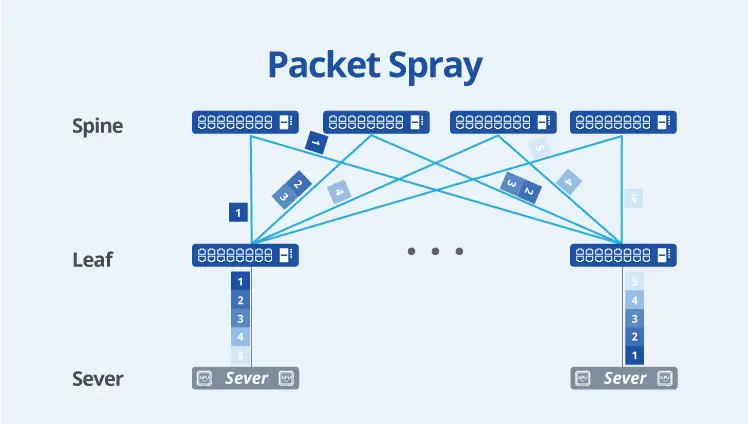
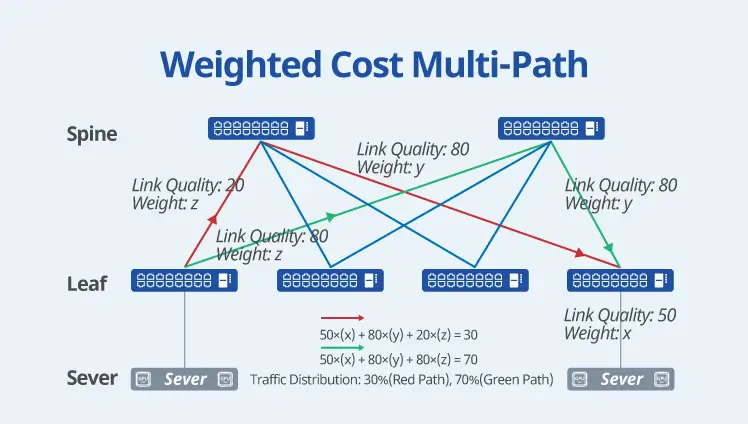
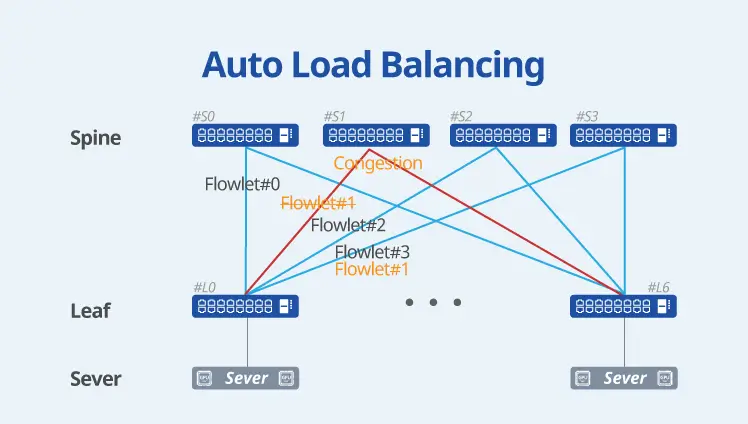
Optimized Features for AI/ML/HPC
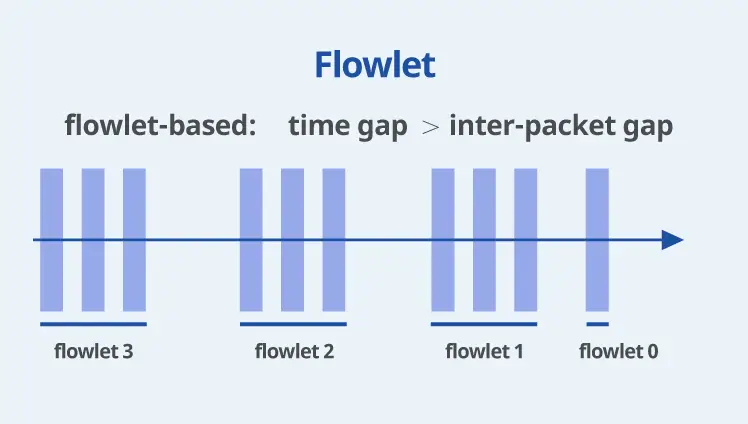
Asterfusion Enterprise SONiC is optimized for AI/ML/HPC scenarios, significantly enhancing traffic management through technologies such as Flowlet and Auto Load Balancing. It also supports dynamic intelligent traffic distribution (Packet Spray); efficient and resilient path selection via WCMP (Weighted Cost Multi-Path); and real-time, precise telemetry routing based on INT Driven Routing.
HIGHLIGHT
Asterfusion Network Monitoring & Visualization
AsterNOS supports Node Exporter to send CPU, traffic, packet loss, latency, and RoCE congestion metrics to Prometheus. Paired with Grafana, it enables real-time, visual insight into network performance.


HIGHLIGHT
O&M in Minutes, Not Days
Automate with Easy RoCE, ZTP, Python and Ansible, SPAN / ERSPAN Monitoring & more—cutting config time, errors, and costs.
Asterfusion 800G Switch Outperforms InfiniBand in AI Inference with Higher TGR and Lower Latency
In AI inference networks, the Asterfusion 800G switch delivers higher TGR (Token Generation Rate) and lower P90ITL (90th Percentile Inter-Token Latency) compared to InfiniBand, demonstrating faster inference speed and greater overall throughput performance.

Reviews
There are no reviews yet.