400G vs 800G Switch: How to Actually Choose
Not every AI cluster needs 800G. Not every 400G deployment will age well. Here’s a frank, numbers-first breakdown — covering topology math, transceiver costs, GPU scale thresholds, and the two products that anchor each tier.
Let’s get something out of the way first. The question isn’t really “400G or 800G?” The question is: how many GPUs are you running today, how many will you need in 18 months, and what does your per-GPU bandwidth look like? Answer those three questions and the switch decision practically makes itself.
If you’re here because someone on your team is pushing for 800G “to future-proof” a 300-GPU cluster, this guide will give you the ammo to push back — or validate their case if the cluster is actually headed to 2,000+ cards. And if you’re genuinely staring down a 5,000-GPU build, we’ll show you why 400G would quietly become your biggest regret.
The Real Differences Between 400G and 800G
On paper: 800G is double the bandwidth. In practice: the gap is architectural, not just numerical. The chip inside matters as much as the port speed printed on the front panel.
The Asteraix CX732Q-N (400G) and CX864E-N (800G) both run on Marvell Teralynx silicon. The 400G uses Teralynx 7 delivering 12.8Tbps total, while the 800G runs on the 5nm Teralynx 10 — a 51.2Tbps monster that’s essentially four 12.8T chips collapsed into one. That consolidation is what enables the architectural differences that actually matter for large-scale AI.
| Spec | CX732Q-N · 400G | CX864E-N · 800G |
|---|---|---|
| Switching Capacity | 12.8 Tbps | 51.2 Tbps |
| Port Count | 32× 400G QSFP-DD | 64× 800G OSFP |
| Port-to-Port Latency | ~500 ns | ~560 ns |
| On-Chip Buffer | 70 MB | 200 MB |
| ASIC | Marvell Teralynx 7 | Marvell Teralynx 10 (5nm) |
| Form Factor | 1U | 2U |
| Max Power | ~550 W (typical) | ~2,200 W (max all-port) |
| RoCEv2 / RDMA | Yes | Yes |
| INT / Telemetry | Yes | Yes (BDC + HDC → Grafana) |
| SONiC NOS | AsterNOS (Enterprise SONiC) | AsterNOS (Enterprise SONiC) |
| UEC Compliance | Partial | Full (line-rate programmable) |
| Price (approx.) | ~$12,000 | ~$46,800 |
Notice the latency numbers. The 800G switch is only 60 ns slower than the 400G. That’s not a typo — the Teralynx 10 is that good. And against Broadcom’s Tomahawk 5 (which sits at around 800 ns), 800G chip is 30% faster at port-to-port latency. That gap matters enormously when you’re running synchronous AllReduce across thousands of GPUs.
What Things Actually Cost (The Part Most Guides Skip)
Every 400G vs 800G comparison focuses on switch CAPEX. Everybody ignores the transceiver cost. This is a serious mistake, especially as you scale past a few hundred ports.
~$400
400G SR4 transceiver (typical)
~$750
800G SR4 transceiver (typical)
~87.5%
Transceiver cost premium for 800G
Run the math on a 1,000-port deployment. At 400G: roughly $400,000 in transceivers. Swap those for 800G SR4: you’re looking at $750,000. That $350,000 delta doesn’t show up in your switch budget — it shows up quietly in your BOM, weeks later, when procurement starts asking questions.
⚠ Hidden CAPEX Trap
At scale, optical transceiver costs routinely exceed the cost of the switches themselves. When someone shows you a 400G-to-800G TCO comparison, ask them what transceiver pricing they used. If they say “we’ll figure that out later,” that’s your red flag.
This isn’t an argument against 800G — it’s an argument for going in with clear eyes. At 5,000+ GPU scale, the performance headroom and topology simplification of 800G more than justify the premium. But at 300 GPUs, that premium delivers zero benefit while burning budget you could spend on actual compute.
Topology Math: The 512-GPU Trap Nobody Talks About
Here’s the practical constraint that should drive your decision more than any spec sheet: the two-tier network ceiling.
With standard 32-port 400G switches in a Spine-Leaf (non-converged) topology, a flat two-tier architecture maxes out at 512 GPUs. Cross that threshold and you’re forced into a three-tier Super-Spine architecture — which means more optical hops, higher end-to-end latency, and a dramatic jump in transceiver and cabling costs (this is what we call the second explosion).
The way around this at 400G is high-density 64-port 400G switches, which push that two-tier ceiling all the way to 2,048 GPUs. That’s where CX-series high-density 400G becomes genuinely compelling for medium-scale AI builds.
“The network doesn’t just ‘slow down’ at the wrong topology — it becomes the primary constraint on GPU utilization. You can have perfect hardware everywhere else and still watch your GPUs idle.”
— Asterfusion engineering notes
800G changes this equation entirely. Because each port carries double the bandwidth, you can sustain a flat two-tier topology up to approximately 5,000 GPUs with 800G Spine-Leaf, avoiding the cabling complexity that kills mid-scale builds. And if you’re thinking Dragonfly or Dragonfly+ topologies for ultra-large clusters — those become practically viable only at 800G port densities.
Four Deployment Scenarios: Where Do You Land?
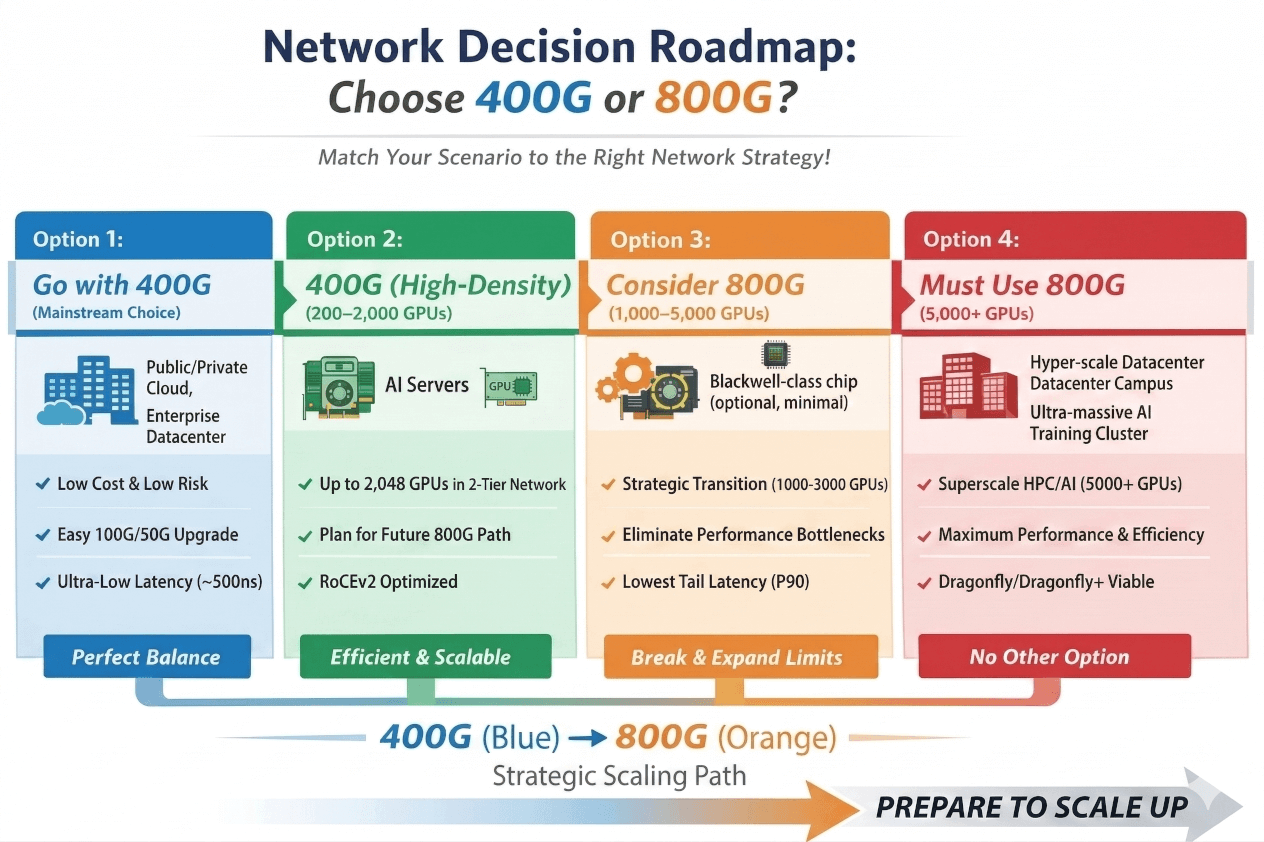
Scenario 01
Choose 400G
Traditional Cloud / Enterprise DC / CPU-Heavy Workloads
Mature ecosystem, low transceiver costs, zero retraining for your ops team. 100G/50G backward compatibility works seamlessly. ~500ns cut-through latency handles microservices and NVMe-oF without breaking a sweat. This is the no-regrets choice for general compute.
Scenario 02
Choose 400G (High-Density)
Medium-Scale AI · Hundreds to ~2,000 GPUs
Standard RoCE at 400G fully handles most training workloads short of frontier model scale. Key: use high-density 64-port 400G switches to stay in a flat two-tier topology. The moment you go three-tier at this scale, your cost and latency story collapses.
Scenario 03
Consider 800G
Strategic Crossover · 1,000–5,000 GPUs
Approaching the physical ceiling of 400G two-tier topology. If your AI servers are already shipping with 800G NICs (Blackwell, ConnectX-8), the network must keep up or GPUs will idle waiting on the fabric. Future-expanding to 3,000+ GPUs mid-lifecycle? Start with 800G now to avoid a painful architecture teardown.
Scenario 04
800G Is Non-Negotiable
Superscale AI / HPC · 5,000–10,000+ GPUs
At this scale on 400G, you’re looking at three or four-tier topologies, optical module counts that grow exponentially, and a single-point failure blast radius that will keep your ops team awake at night. 800G isn’t a nice-to-have — it’s the only architecture that keeps TCO rational at this tier.
Beyond Bandwidth: The Three Factors That Actually Determine AI Training Speed
If you’re buying a switch for an AI cluster, headline bandwidth is almost the least interesting spec. Here’s what actually determines whether your GPUs are working or waiting:
1. Buffer Depth and Congestion Control
Large-scale synchronous AI training (AllReduce, FSDP, tensor parallelism) creates savage traffic bursts — hundreds of nodes all talking simultaneously in tight synchronization windows. A switch with insufficient buffer will drop packets. Dropped packets mean GPU stalls. GPU stalls burn money proportional to your hardware spend.
The CX732Q-N carries 70 MB of intelligent on-chip buffer — competitive at 400G tier. The CX864E-N doubles that to 200 MB, well ahead of the Broadcom TH5’s 165 MB. Combined with ECN/PFC support and fine-grained QoS, these buffers absorb microburst spikes that would cripple lesser hardware.
2. Latency — The Real Kind, Not the Marketing Kind
Some vendors publish latency numbers measured under minimal load. Look for latency measured at line-rate forwarding of standard Ethernet packets. Asteraix publishes both 500 ns (CX732Q-N) and 560 ns (CX864E-N) under those real conditions.
In head-to-head testing against InfiniBand — the historical benchmark for AI cluster networking — the CX864E-N delivered 20.4% lower P90 tail latency and 27.5% higher TCR (Token Completion Rate). That’s not a marginal win. For inference workloads where every token generation matters, it’s a meaningful competitive edge.
3. Power Efficiency and Long-Term OPEX
A 10,000-GPU cluster might run for five or six years. The power bill over that lifetime can dwarf the initial hardware spend. Asteraix’s CX864E-N measured 2,200 W maximum power consumption with all 64 ports fully loaded — a figure that holds up well when you’re considering cooling infrastructure and PUE at hyperscale.
✓ Operator Note
The CX864E-N supports In-Band Network Telemetry (INT) with BDC and HDC metrics exportable to Prometheus, with visualization via Grafana. This is production-grade observability out of the box — not a lab feature. Knowing where your congestion is, in real time, changes how you debug and provision capacity.
800G changes this equation entirely. Because each port carries double the bandwidth, you can sustain a flat two-tier topology up to approximately 5,000 GPUs with 800G Spine-Leaf, avoiding the cabling complexity that kills mid-scale builds. And if you’re thinking Dragonfly or Dragonfly+ topologies for ultra-large clusters — those become practically viable only at 800G port densities.
The Two Products Worth Looking At
Asteraix offers the full CX-N lineup, but if you’re choosing between 400G and 800G today, these are the two flagship data center switches to evaluate:
400G Data Center Switch
CX732Q-N
32× 400G QSFP-DD · Marvell Teralynx · Enterprise SONiC
Total Capacity
12.8 Tbps
Latency
~500 ns
Buffer
70 MB
Form Factor
1U
RDMA / RoCEv2
Yes
NOS
AsterNOS (SONiC)
Best For
Up to ~2,048 GPUs (flat 2-tier)
800G Data Center Switch
CX864E-N
64× 800G OSFP · Marvell Teralynx 10 · Enterprise SONiC
Total Capacity
51.2 Tbps
Latency
~560 ns
Buffer
200 MB
Form Factor
2U
RDMA / RoCEv2
Yes
NOS
AsterNOS (SONiC)
Best For
1,000–10,000+ GPU clusters
Both switches ship with AsterNOS pre-installed — enterprise SONiC distribution. It includes the best available SAI support, BGP-EVPN, VXLAN (up to 4K groups), 256-way ECMP, gNMI/REST/NETCONF management interfaces, and PTP/1588v2 for timing-sensitive environments. You’re not getting a bare-metal curiosity that needs a month of NOS integration work — it’s production-ready out of the box.
ℹ Also Available
If you’re looking for a 400G switch based on Marvell Falcon (rather than Teralynx) for more cost-sensitive deployments or campus aggregation roles, check out the CX732Q-N Falcon variant — same port count, 1,900ns latency, priced from ~$11,999.
Quick Decision Guide: Stop Overthinking It
Here’s the honest summary. Neither option is wrong in the right context.
Go 400G if: your cluster is under 2,000 GPUs, you’re running general-purpose or CPU-heavy workloads, your ops team has 100G/400G experience, and you need strong TCO discipline. The CX732Q-N at 500ns latency and 70MB buffer handles the vast majority of real-world AI training just fine.
Go 800G if: your cluster is pushing past 1,500 GPUs and expanding, your servers are already shipping with 800G NICs (Blackwell-generation hardware), you’re planning for 5,000+ GPU builds and want to avoid a topology overhaul mid-project, or you simply cannot afford the tail latency variation that comes with multi-tier 400G at scale. The CX864E-N beating InfiniBand at P90 latency isn’t a paper result — it’s validated in production deployments at hyperscalers.
The least useful thing you can do is pick based on a number on a box. Pick based on topology, GPU count trajectory, NIC generation, and the cost math on transceivers. Those four variables tell the whole story.
“There is no universally ‘best’ speed — only the one that best fits your workload. Understanding your application comes before choosing your bandwidth.”